Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-X2: More Performance, Deeper OoO
We first start off with the Cortex-X2, successor to last year’s Cortex-X1. The X1 marked the first in a new IP line-up from Arm which diverged its “big” core offering into two different IP lines, with the Cortex-A sibling continuing Arm’s original design philosophy of PPA, while the X-cores are allowed to grow in size and power in order to achieve much higher performance points.
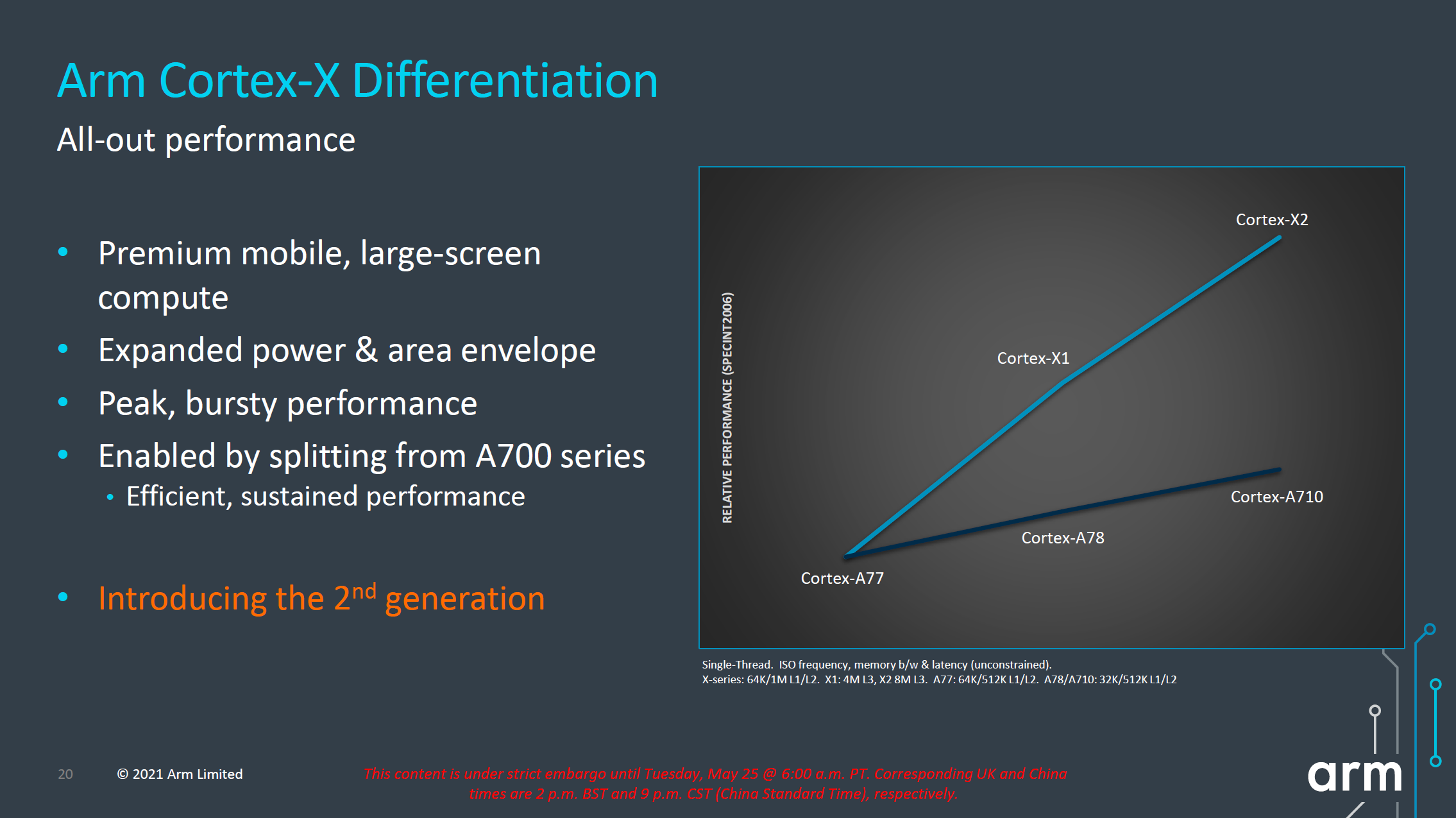
The Cortex-X2 continues this philosophy, and further grows the performance and power gap between it and its “middle” sibling, the Cortex-A710. I also noticed that throughout Arm’s presentation there were a lot more mentions of having the Cortex-X2 being used in larger-screen compute devices and form-factors such as laptops, so it might very well be an indication of the company that some of its customers will be using the X2 more predominantly in such designs for this generation.

From an architectural standpoint the X2 is naturally different from the X1, thanks in large part to its support for Armv9 and all of the security and related ISA platform advancements that come with the new re-baselining of the architecture.
As noted in the introduction, the Cortex-X2 is also a 64-bit only core which only supports AArch64 execution, even in PL0 user mode applications. From a microarchitectural standpoint this is interesting as it means Arm will have been able to kick out some cruft in the design. However as the design is a continuation of the Austin family of processors, I do wonder if we’ll see more benefits of this deprecation in future “clean-sheet” big cores designs, where AArch64-only was designed from the get-go. This, in fact, is something that's already happening in other members of Arm's CPU cores, as the new little core Cortex-A510 was designed sans-AArch32.
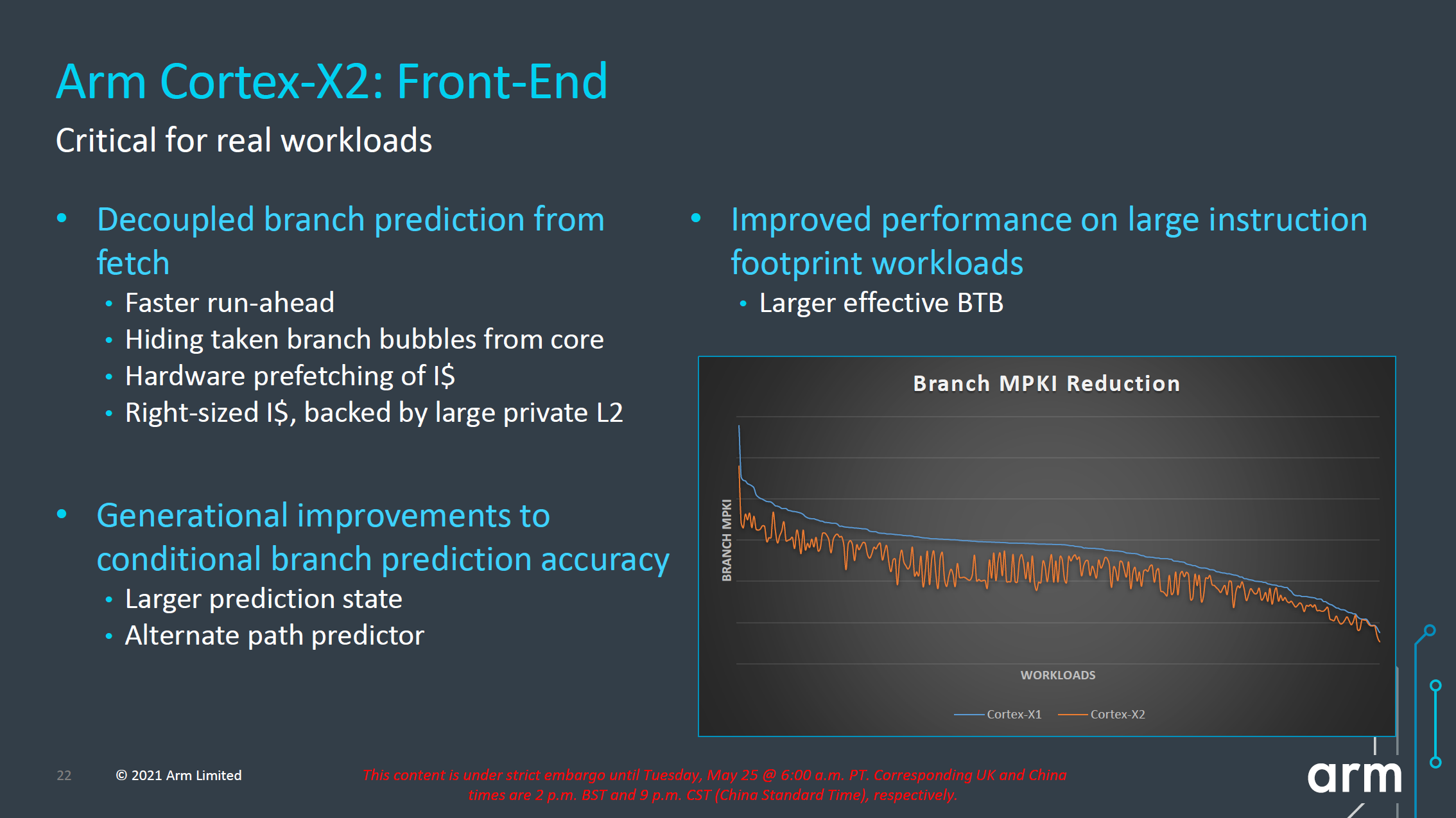
Starting off with the front-end, in general, Arm has continued to try to improve what it considers the most important aspect of the microarchitecture: branch prediction. This includes continuing to run the branch resolution in a decoupled way from the fetch stages in order to being able to have these functional blocks be able to run ahead of the rest of the core in case of mispredicts and minimize branch bubbles. Arm generally doesn’t like to talk too much details about what exactly they’ve changed here in terms of their predictors, but promises a notable improvement in terms of branch prediction accuracy for the new X2 and A710 cores, effectively reducing the MPKI (Misses per kilo instructions) metric for a very wide range of workloads.
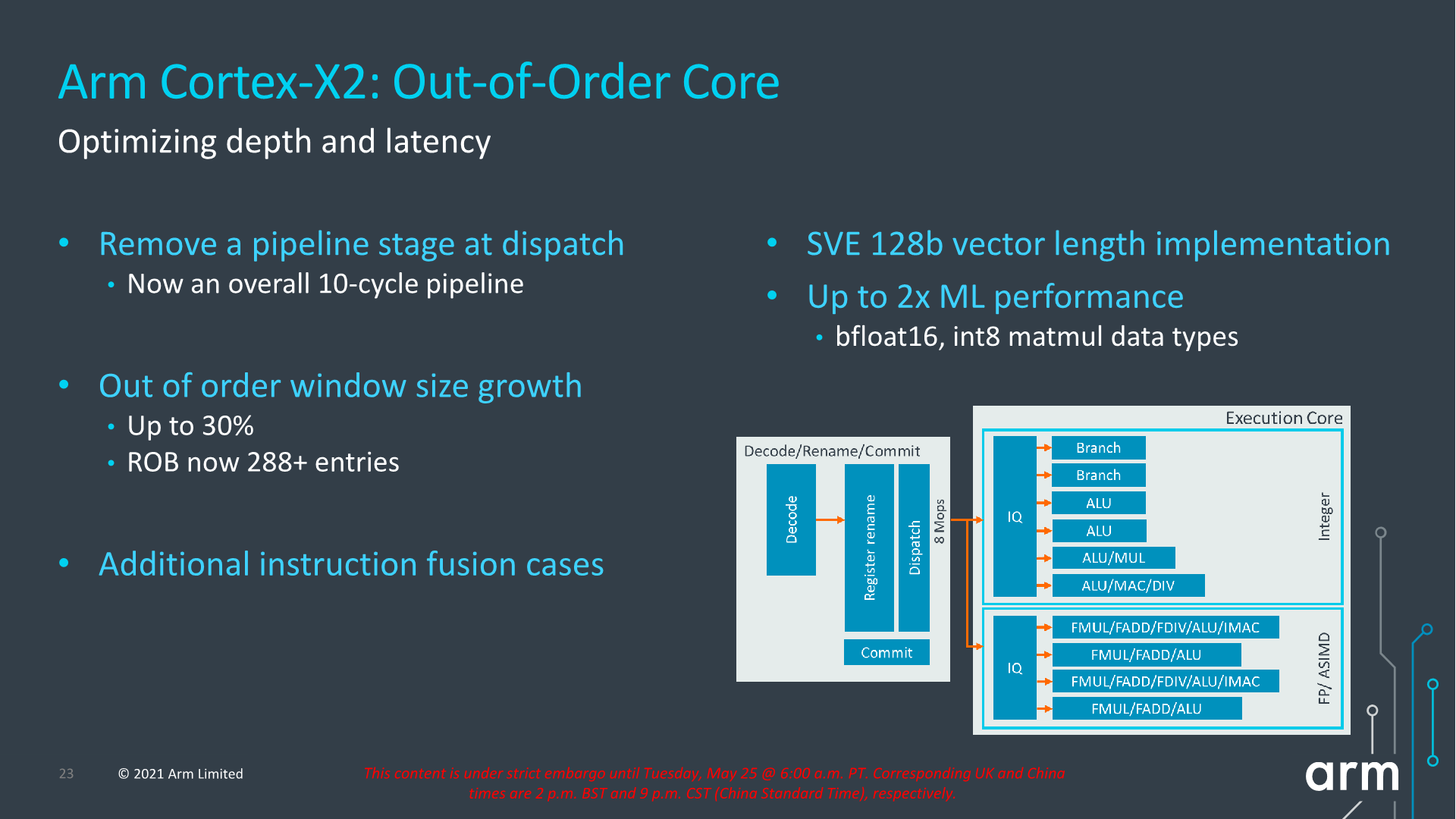
The new core overall reduces its pipeline length from 11 cycles to 10 cycles as Arm has been able to reduce the dispatch stages from 2-cycles to 1-cycle. It’s to be noted that we have to differentiate the pipeline cycles from the mispredict penalties, the latter had already been reduced to 10 cycles in most circumstances in the Cortex-A77 design. Removing a pipeline stage is generally a rather large change, particularly given Arm’s target of maintaining frequency capabilities of the core. This design change did incur some more complex engineering and had area and power costs; but despite that, as Arm explains in, cutting a pipeline stage still offered a larger return-on-investment when it came to the performance benefits, and was thus very much worth it.
The core also increases its out-of-order capabilities, increasing the ROB (reorder buffer) by 30% from 224 entries to 288 entries this generation. The effective figure is actually a little bit higher still, as in cases of compression and instruction bundling there are essentially more than 288 entries being stored. Arm says there’s also more instruction fusion cases being facilitated this generation.
On the back-end of the core, the big new change is on the part of the FP/ASIMD pipelines which are now SVE2-capable. In the mobile space, the SVE vector length will continue to be 128b and essentially the new X2 core features similar throughput characteristics to the X1’s 4x FP/NEON pipelines. The choice of 128b vectors instead of something higher is due to the requirement to have homogenous architectural feature-sets amongst big.LITTLE designs as you cannot mix different vector length microarchitectures in the same SoC in a seamless fashion.
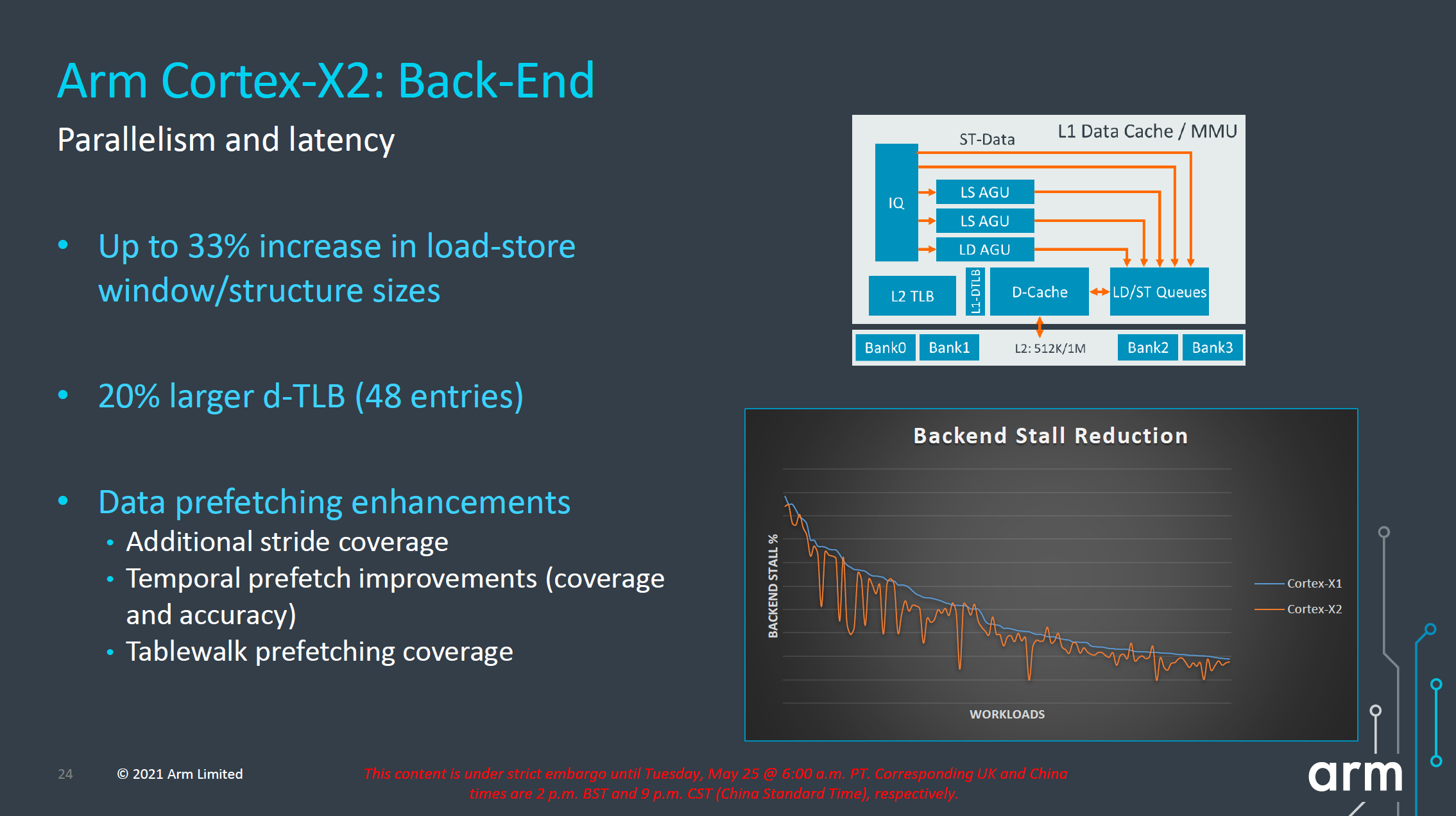
On the back-end, the Cortex-X2 continues to focus on increasing MLP (memory level parallelism) by increasing the load-store windows and structure sizes by 33%. Arm here employs several structures and generally doesn’t go into detail about exactly which queues have been extended, but once we get our hands on X2 systems we’ll be likely be able to measure this. The L1 dTLB has grown from 40 entries to 48 entries, and as with every generation, Arm has also improved their prefetchers, increasing accuracies and coverage.
One prefetcher that surprised us in the Cortex-X1 and A78 earlier this year when we first tested new generation devices was a temporal prefetcher – the first of its kind that we’re aware of in the industry. This is able to latch onto arbitrary repeated memory patterns and recognize new iterations in memory accesses, being able to smartly prefetch the whole pattern up to a certain depth (we estimate a 32-64MB window). Arm states that this coverage is now further increased, as well as the accuracy – though again the details we’ll only able to see once we get our hands on silicon.
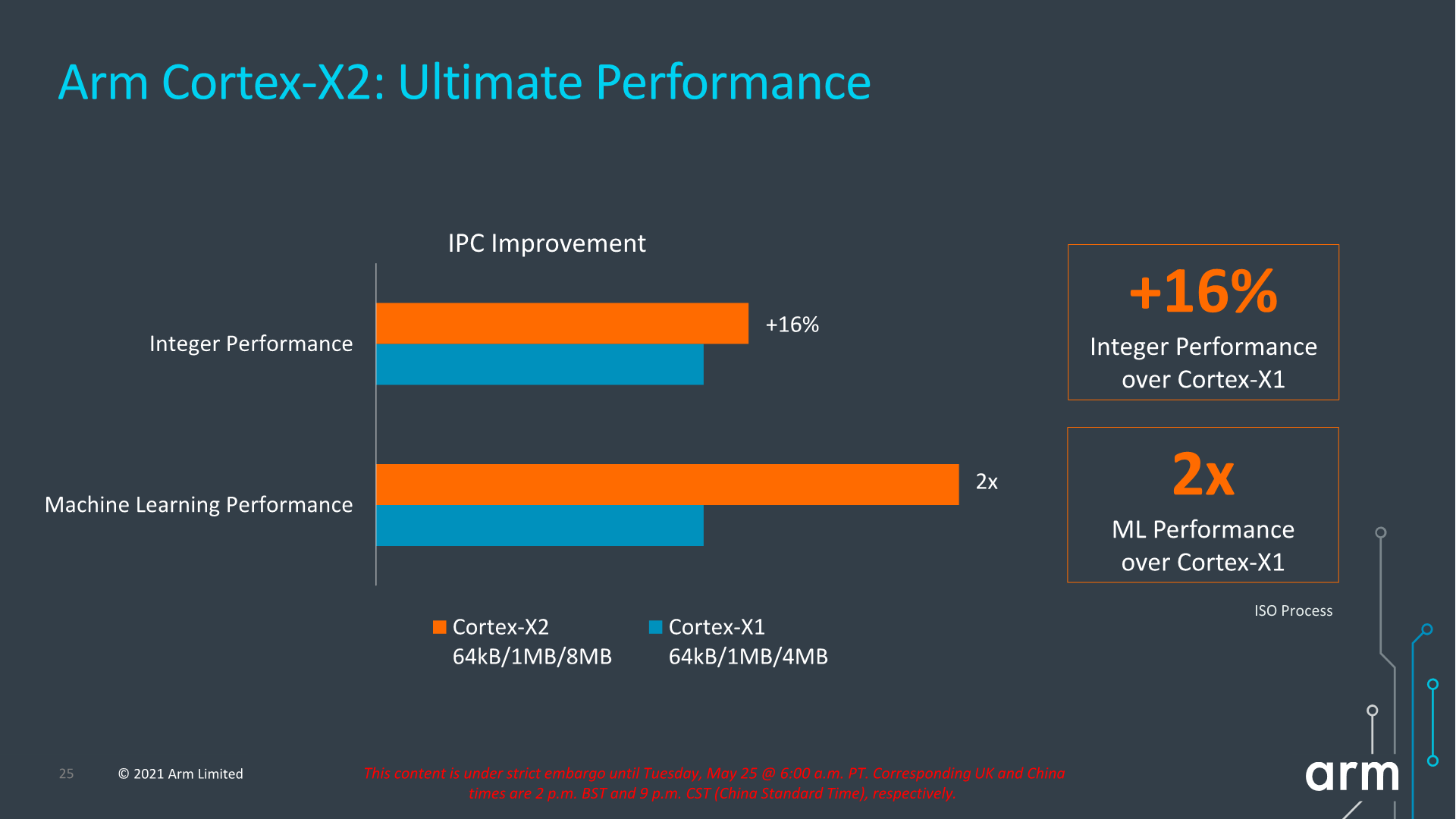
In terms of IPC improvements, this year’s figures are quoted to reach +16% in SPECint2006 at ISO frequency. The issue with this metric (and which applies to all of Arm’s figures today) is that Arm is comparing an 8MB L3 cache design to a 4MB L3 design, so I expect a larger chunk of that +16% figure to be due to the larger cache rather than the core IPC improvements themselves.
For their part, Arm is reiterating that they're expecting 8MB L3 designs for next year’s X2 SoCs – and thus this +16% figure is realistic and is what users should see in actual implementations. But with that said, we had the same discussion last year in regards to Arm expecting 8MB L3 caches for X1 SoCs, which didn't happen for either the Exynos 2100 nor the Snapdragon 888. So we'll just have to wait and see what cache sizes the flagship commercial SoCs end up going with.

In terms of the performance and power curve, the new X2 core extends itself ahead of the X1 curve in both metrics. The +16% performance figure in terms of the peak performance points, though it does come at a cost of higher power consumption.
Generally, this is a bit worrying in context of what we’re seeing in the market right now when it comes to process node choices from vendors. We’ve seen that Samsung’s 5LPE node used by Qualcomm and S.LSI in the Snapdragon 888 and Exynos 2100 has under-delivered in terms of performance and power efficiency, and I generally consider both big cores' power consumption to be at a higher bound limit when it comes to thermals. I expect Qualcomm to stick with Samsung foundry in the next generation, so I am admittedly pessimistic in regards to power improvements in whichever node the next flagship SoCs come in (be it 5LPP or 4LPP). It could well be plausible that we wouldn’t see the full +16% improvement in actual SoCs next year.








181 Comments
View All Comments
ChrisGX - Thursday, May 27, 2021 - link
Yes, @melgross, @mattbe and @mode_13h are absolutely right. Apple has an architectural license from ARM, viz. a license for the ARM ISA rather than any physical IP. Not deterred by that some individuals commenting here seem to want to suggest that Apple has infringed on ARM's IP or somehow by nefarious means has acquired crucial information about proprietary tech found in ARM chips without stumping up the cash for it. These suggestions are pathetic. If a patent infringement is being alleged please tell us the patent number so that we can determine for ourselves whether there really has been a patent infringement. Or, is a criminal conspiracy with other parties to steal trade secrets from ARM being asserted? There is an obvious problem with that idea. Does anyone seriously suppose that ARM would fail to have Apple before a court demanding a huge settlement for theft of trade secrets, if it had any reason to think that Apple had been engaged in such an exercise? Uninformed individuals are just making up things that chime with their sense of how things must be. Hmm...here's a thought. If you know so little about a topic that you wouldn't be willing to stake your reputation on it or swear to in a court, say, then perhaps saying nothing on the topic would be a better choice than pretending to possess knowledge that you so obviously don't possess.mode_13h - Saturday, May 29, 2021 - link
> Uninformed individuals are just making up things that chime with> their sense of how things must be.
Welcome to the world of internet comment forums.
> If you know so little about a topic that you wouldn't be willing to stake your reputation on it
We don't do "reputation". Everybody is on equal footing, here. Just challenge them with facts, references, and sound logic.
jeremyshaw - Tuesday, May 25, 2021 - link
Thanks SarahKerrigan, igor velky. I was mostly thinking of configurations we didn't commonly see. We have seen 4xLITTLE, 2xbig.4xLITTLE, etc even the 8xA78C. The slides on page 5 cover setups we have seen before. Mostly curious if the fabric is tied to specific configs like was implied at the 8xA78C launch, or if it's flexible enough to have, say, two X2, two A710, four A510, or something like one X2 with four A510 (like Intel's Lakefield), etc. IMO, there are a lot of embedded controllers that don't need a lot of CPU throughput, but can benefit from one faster core for UI.Kangal - Saturday, May 29, 2021 - link
I'm more interested in seeing a 3+5 design.The "Large Cores" just aren't good on a phone, a tablet maybe, not on a phone. We're already getting throttling on the "Medium Cores" (eg Cortex A78/A710). And most tasks on Android are handled great in Dualcore mode, and very few in Quad-core mode, when looking at the schedulers. So Three Medium Cores will offer 95% of the performance of your regular flagship processor. Extending the Small Cores to a group of five, also can help efficiency by having more performance in the lower zone, reducing the amount of times the large cores need to be stressed.
However, with what was announced today, we can actually expect a REDUCTION in 2022 ARM processors compared to 2021 ARM processors. I mean we're talking about 10% gains in X2, 10% gains in A710, and 1% gains in A510, when compared to a design that should be on a better node with better cache. That's not guaranteed with the continuing Chip Shortage. IN FACT most chipmakers are willing to "cheap out" and simply use the marketing of "running on ARMv9" to justify the higher cost and lower performance.
They stuffed up with the naming scheme btw. And they really stuffed up by not removing 32-bit support completely. And they stuffed up with not doing a blank-sheet approach, for a revolutionary ARMv9 design. We're going to see the smallest gains in Android Phones, just like it happened when people were comparing the QSD 800/801/805 to the QSD 808/810 (Cortex A57) back in 2015. Which hopefully means ARMs other divisions in UK/France can pick the slack and come with a proper successor. This would be the Cortex A72 to their Cortex A57, a la, 2022 A710 versus the 2023 A730. Though I doubt the little cores will get any improvement besides a 10% bump due to the node lithography improvements.
psychobriggsy - Monday, June 21, 2021 - link
Theoretically this should support 16 A510s (8 clusters), as each cluster shares a port on the interconnect.We may see 2X 4B 4L configurations (10 cores) one day, but in the main I guess we're stuck with 1X 3B 4L (8L?) options. I see budget chips using 4L+4L (wider FP on some).
Wonder if there's room for an A310 chip (4 int cores per cluster, 1 shared FP, 2-wide).
docola - Tuesday, May 25, 2021 - link
does the shift to 64 bit cpus and apps mean that todays phone will startbecoming obsolete starting next year?
iphonebestgamephone - Tuesday, May 25, 2021 - link
If you are on a 32 bit phone yeahdocola - Tuesday, May 25, 2021 - link
fun... so this means i shouldnt buy an expensive phone for another 1 or 2 years,because this is gonna be one of those rare REAL shift in tech... sigh....
supdawgwtfd - Tuesday, May 25, 2021 - link
Current phones support 64bit instructions...No need to delay.
docola - Tuesday, May 25, 2021 - link
great thanks! i know i sound ignorant in here oh well