The Apple A15 SoC Performance Review: Faster & More Efficient
by Andrei Frumusanu on October 4, 2021 9:30 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- Apple A15
GPU Performance - Great GPU, So-So Thermals Designs
The GPUs on the A15 iPhones are interesting, this is the first time that Apple has functionally segmented the GPU configurations on their SoCs within the iPhone device range, with the iPhone 13 mini and iPhone 13 receiving a 4-core GPU, similar to the A14 devices last year, while the 13 Pro and 13 Pro Max receive a 5-core variant of the SoC. It’s still the same SoC and silicon chip in both cases, just that Apple is disabling one GPU core on the non-Pro models, possibly for yield reasons?
Apple’s performance figures for the GPU were also a bit intriguing in that there weren’t any generational comparisons, just a “+30%” and “+50%” figure against the competition. I initially theorized to mean +10% and +28% against the A14, so let’s see if that pans out:
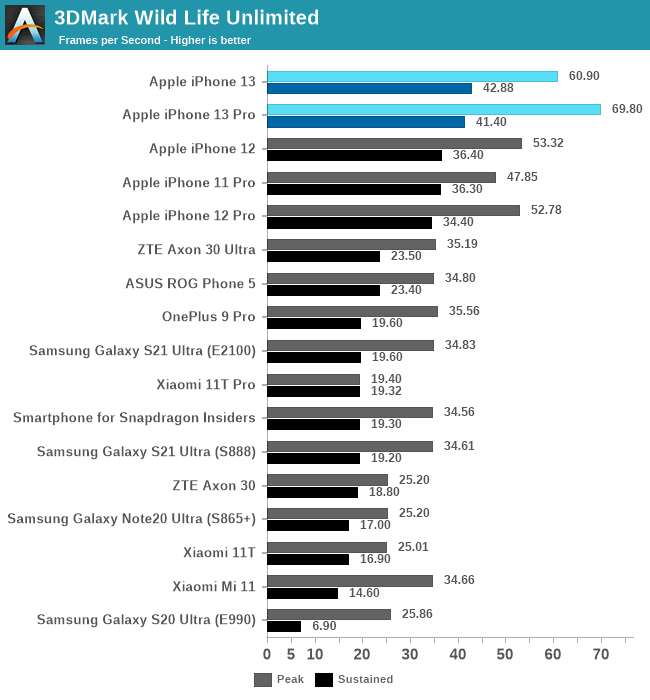
In the 3DMark Wild Life test, we see the 5-core A15 leap the A15 by +30%, while the 4-core showcases a +14% improvement, so quite close to what we predicted. The peak performance here is essentially double that of the nearest competitor, so Apple is likely low-balling things again.
In terms of sustained performance, the new chips continue to showcase a large difference in what they achieve with a cold phone versus a heated phone, interestingly, the 4-core iPhone 13 lands a bit ahead of the 13 Pro here, more on this later.
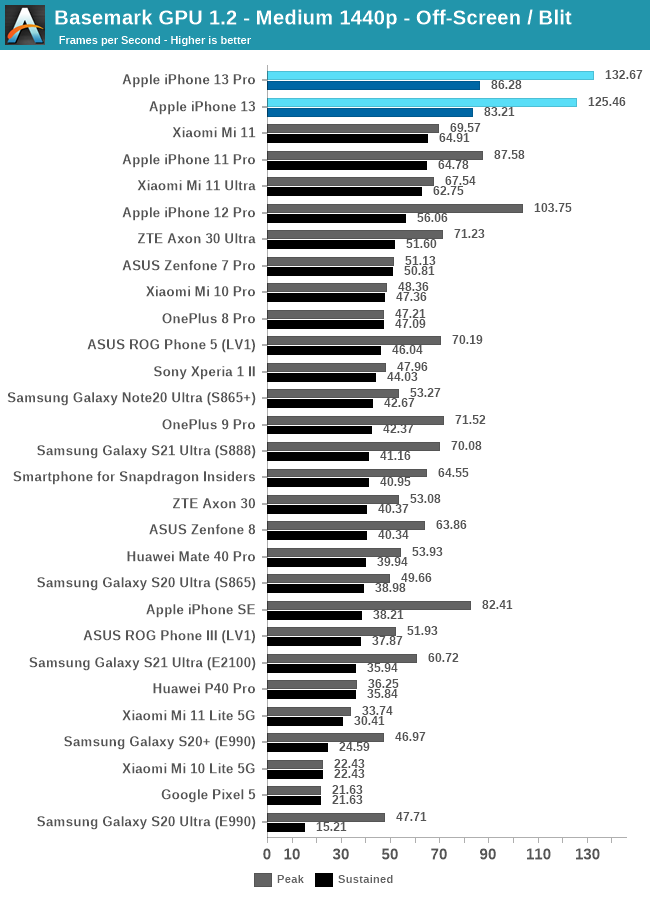
In Basemark GPU, the 13 Pro lands in at +28% over the 12 Pro, with the 4-core iPhone 13 only being slightly slower. Again, the phones throttle hard, however still manage to land with sustained performances well above the peak performances of the competition.
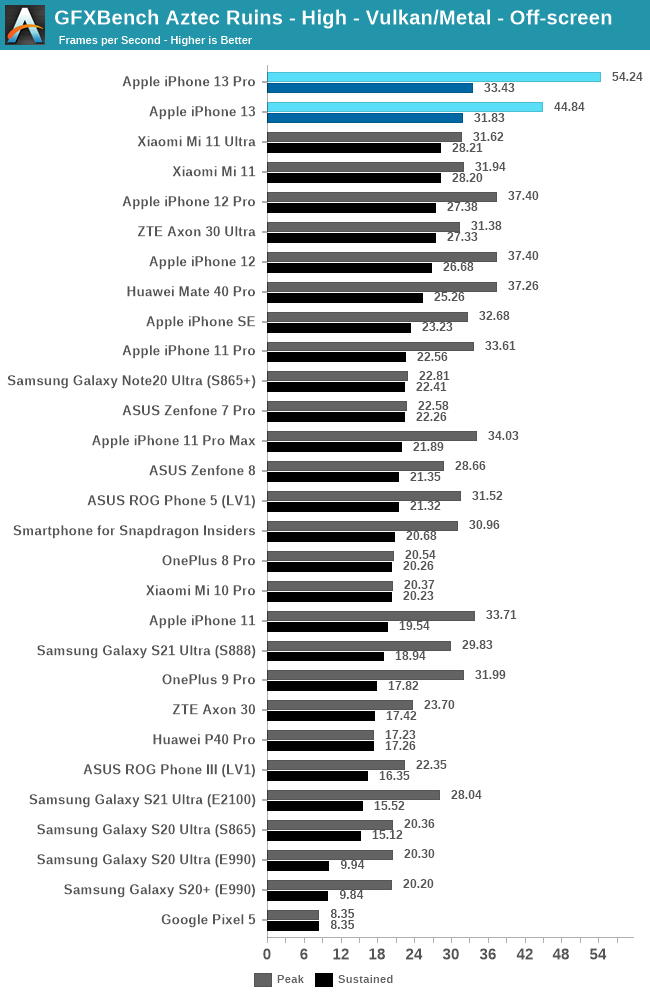
In GFXBench Aztec High, the 13 Pro lands in at a massive +46% performance advantage over the 12 Pro, while the 13 showcases a +19% boost. These are numbers that are above the expectations – in terms of microarchitectural changes the new A15 GPU appears to adopt the same double FP32 throughput as on the M1 GPU, seemingly adding extra units alongside the existing FP32/double-rate FP16 ALUs. The increased 32MB SLC will also likely help a lot with GPU bandwidth and hit-rates, so these two changes seem to be the most obvious explanations for the massive increases.
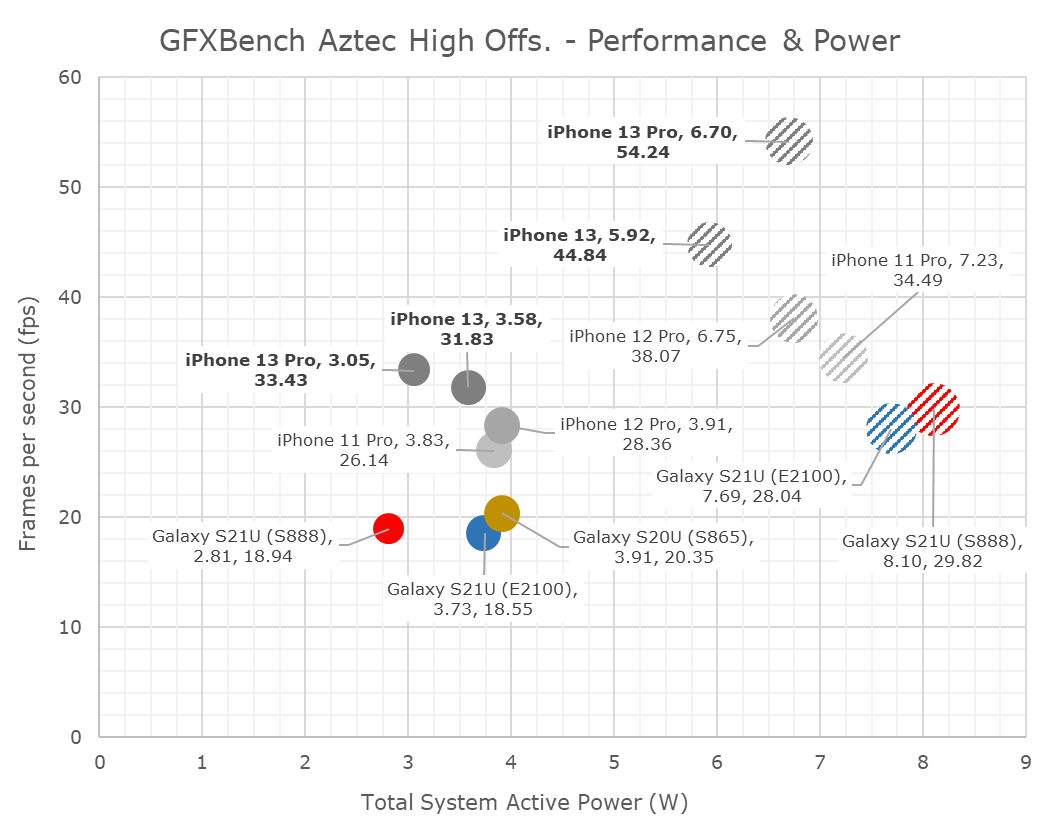
In terms of power and efficiency, I’m also migrating away from tables to bubble charts to better represent the spatial positioning of the various SoCs.
I’d also like to note here that I had went ahead and re-measured the A13 and A14 phones in their peak performance states, showcasing larger power figures than the ones we’ve published in the past. Reason for this is the methodology where we’re only able to measure via input power of the phone, as we cannot dismantle our samples and are lacking PMIC fuelgauge access otherwise. The iPhone 13 figures here are generally hopefully correct as I measured other scenarios up to 9W, however there is still a bit of doubt on whether the phone is drawing from battery or not. The sustained power figures have a higher reliability.
As noted, the A15’s peak performance is massively better, but also appearing that the phone is improving the power draw slightly compared to the A14, meaning we see large efficiency improvements.
Both the 13 and 13 Pro throttle quite quickly after a few minutes of load, but generally at different power points. The 13 Pro with its 5-core GPU throttles down to around 3W, while the 13 goes to around 3.6W.
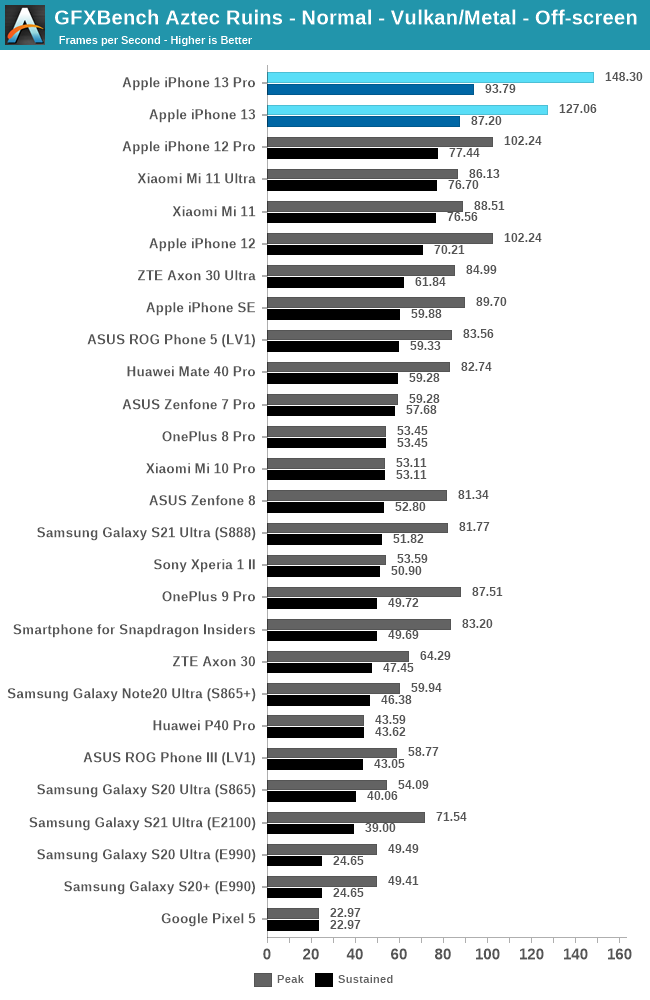
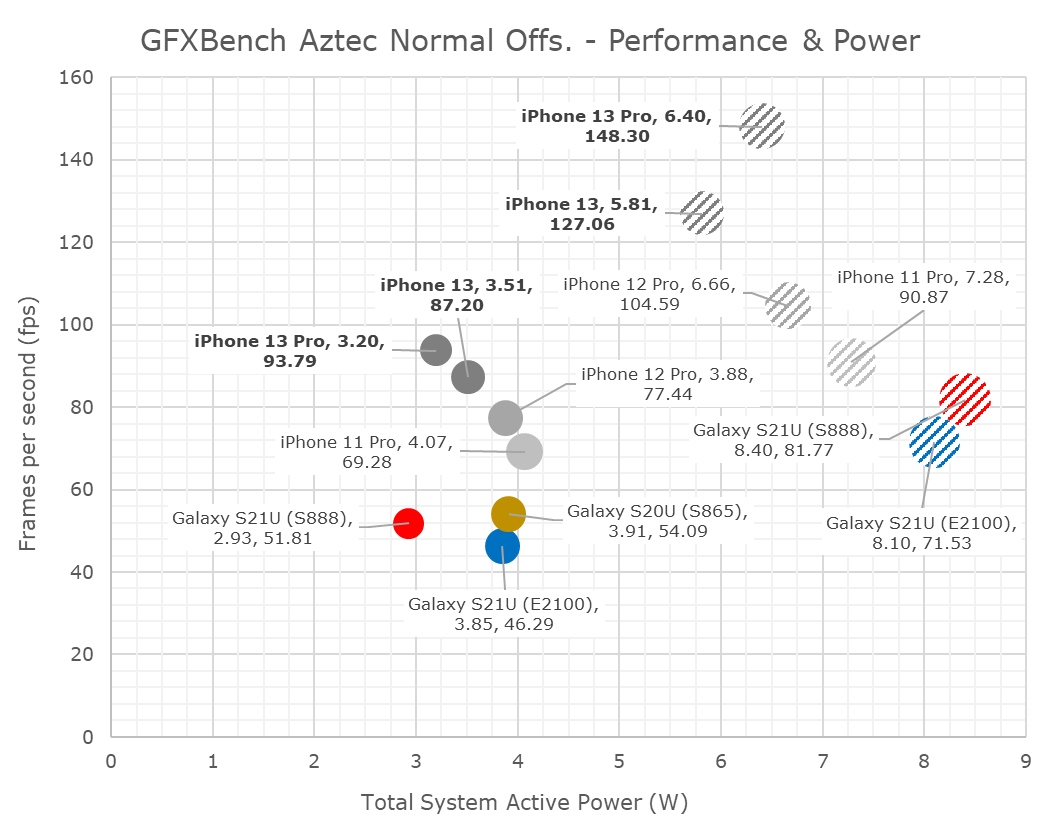
In Aztec Normal, we’re seeing similar relative positioning both in performance and efficiency. The iPhones 13 and 13 Pro are quite closer in performance than expected, due to different throttling levels.
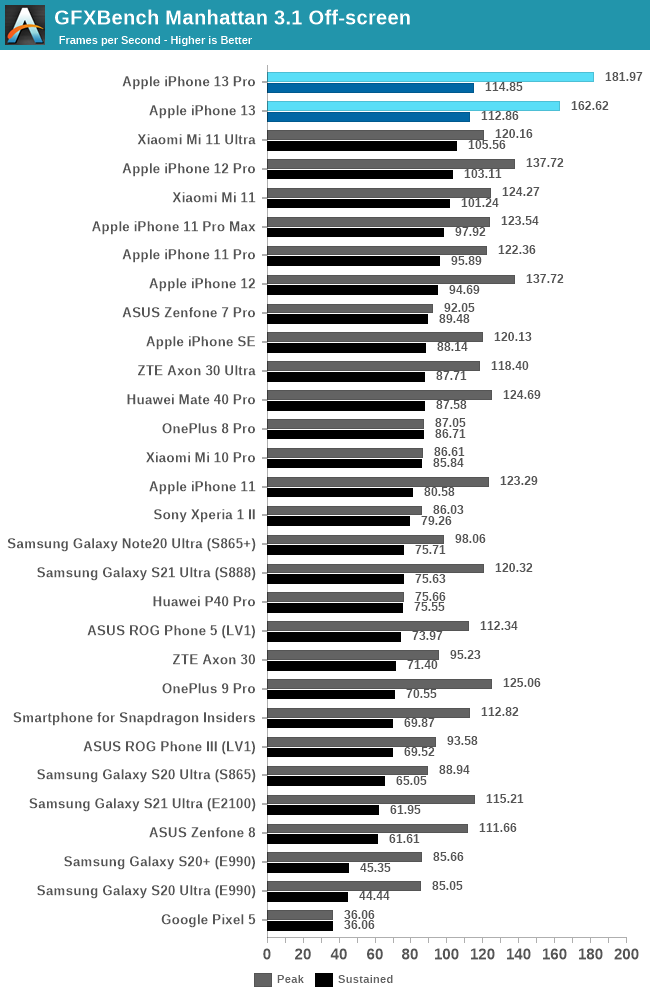
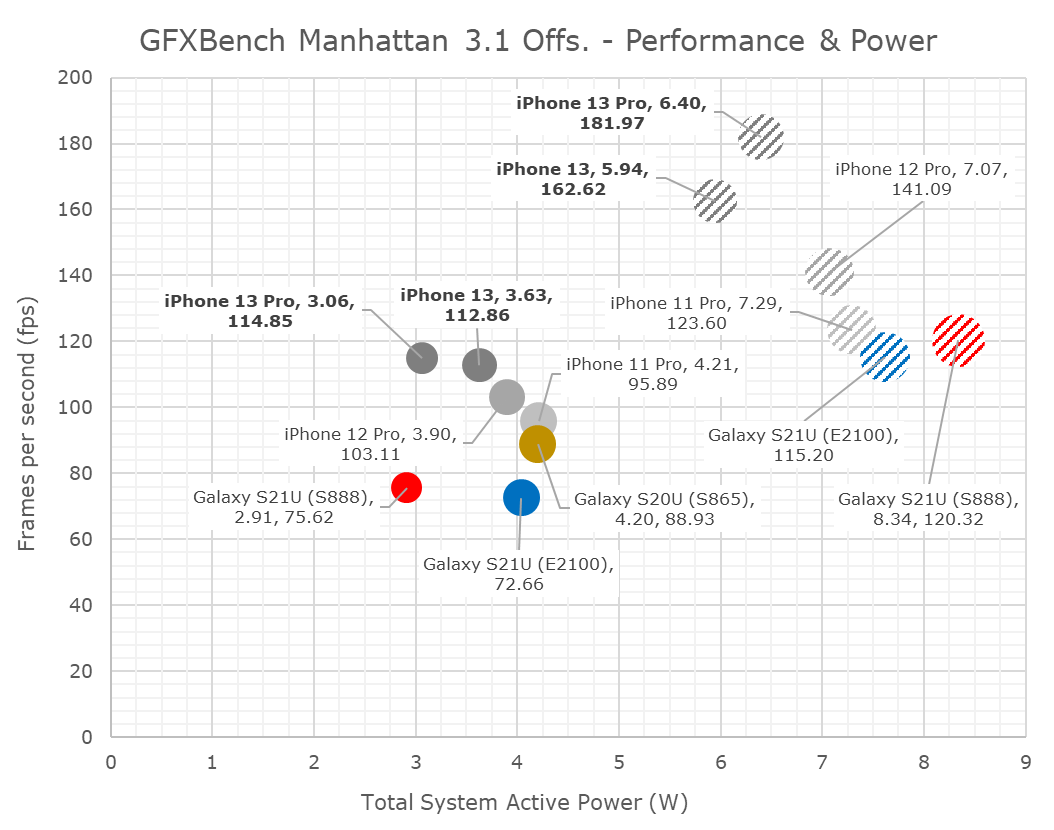
Finally, in Manhattan 3.1, the A15’s 5-core goes up +32%, while the 4-core goes up +18%. The sustained performance isn’t notably different between the two, and also represent smaller improvements over the iPhone 11 and 12 series.
Impressive GPU Performance, but quite limited thermals
Our results here showcase two sides of a coin: In terms of peak performance, the new A15 GPU is absolutely astonishing, and showcasing again improvements that are well above Apple’s marketing claims. The new GPU architecture, and possibly the new SLC allow for fantastic gains in performance, as well as efficiency.
What’s not so great, is the phone’s throttling. Particularly, we seem to be seeing quite reduced power levels on the iPhone 13 Pro, compared to the iPhone 13 as well as previous generation iPhones.


Source: 微机分WekiHome
The 13 Pro models this year come with a new PCB design, that’s even denser than what we’ve had on the previous generations, in order to facilitate the larger battery and new camera modules. What’s been extremely perplexing with Apple’s motherboard designs has been the fact that since they employed dual-layer “sandwich” PCBs, is that they’re packaging the SoC on the inside of the two soldered boards. This comes in contrast to other vendors such as Samsung, who also have adopted the “sandwich” PCB, but the SoC is located on the outer side of the assembly, making direct contact with the heat spreader and display mid-frame.
There are reports of the new iPhones throttling more under gaming and cellular connectivity – well, I’m sure that having the modem directly opposite the SoC inside the sandwich is a contributor to this situation. The iPhone 13 Pro showcasing lower sustained power levels may be tied to the new PCB design, and Apple’s overall iPhone thermal design is definitely amongst the worst out there, as it doesn’t do a good job of spreading the heat throughout the body of the phone, achieving a SoC thermal envelope that’s far smaller than the actual device thermal envelope.
No Apples to Apples in Gaming
In terms of general gaming performance, I’ll also want to make note of a few things – the new iPhones, even with their somewhat limited thermal capacity, are still vastly faster than give out a better gaming experience than competitive phones. Lately benchmarking actual games has been something that has risen in popularity, and generally, I’m all for that, however there are just some fundamental inconsistencies that make direct game comparisons not empirically viable to come to SoC conclusions.
Take Genshin Impact for example, unarguably the #1 AAA mobile game out there, and also one of the most performance demanding titles in the market right now, comparing the visual fidelity on a Galaxy S21 Ultra (Snapdragon 888), Mi 11 Ultra, and the iPhone 13 Pro Max:
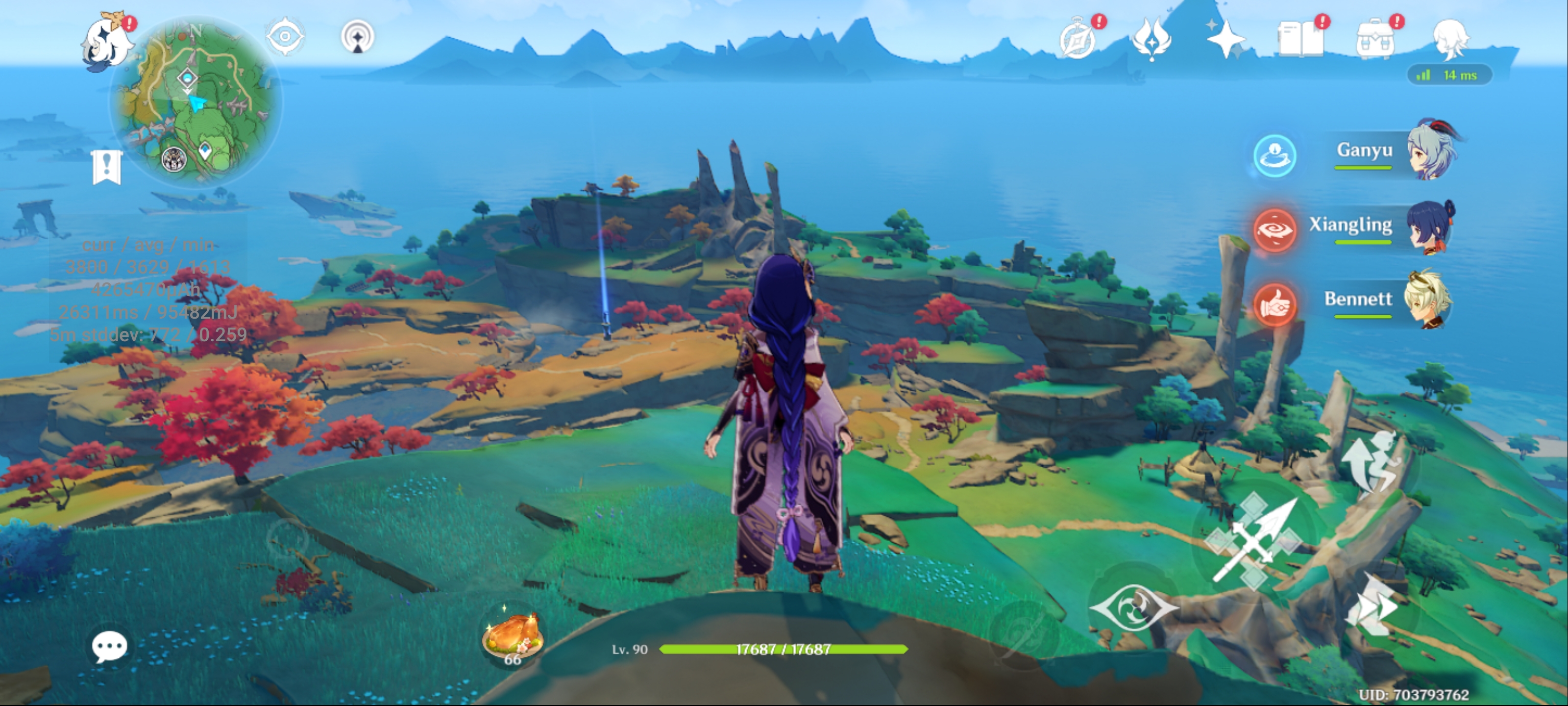
Galaxy S21 Ultra - Snapdragon 888

Mi 11 Ultra - Snapdragon 888
Even though the S21 Ultra and the Mi 11 Ultra both feature the same SoC, they have very different characteristics in terms of thermals. The S21 Ultra generally sustains about 3.5W total device power under the same conditions, while the Mi 11 Ultra will hover between 5-6W, and a much hotter phone. The difference between the two not only exhibits itself in the performance of the game, but also in the visual fidelity, as the S21 Ultra is running much lower resolution due to the game having a dynamic resolution scaling (both phones had the exact same game settings).
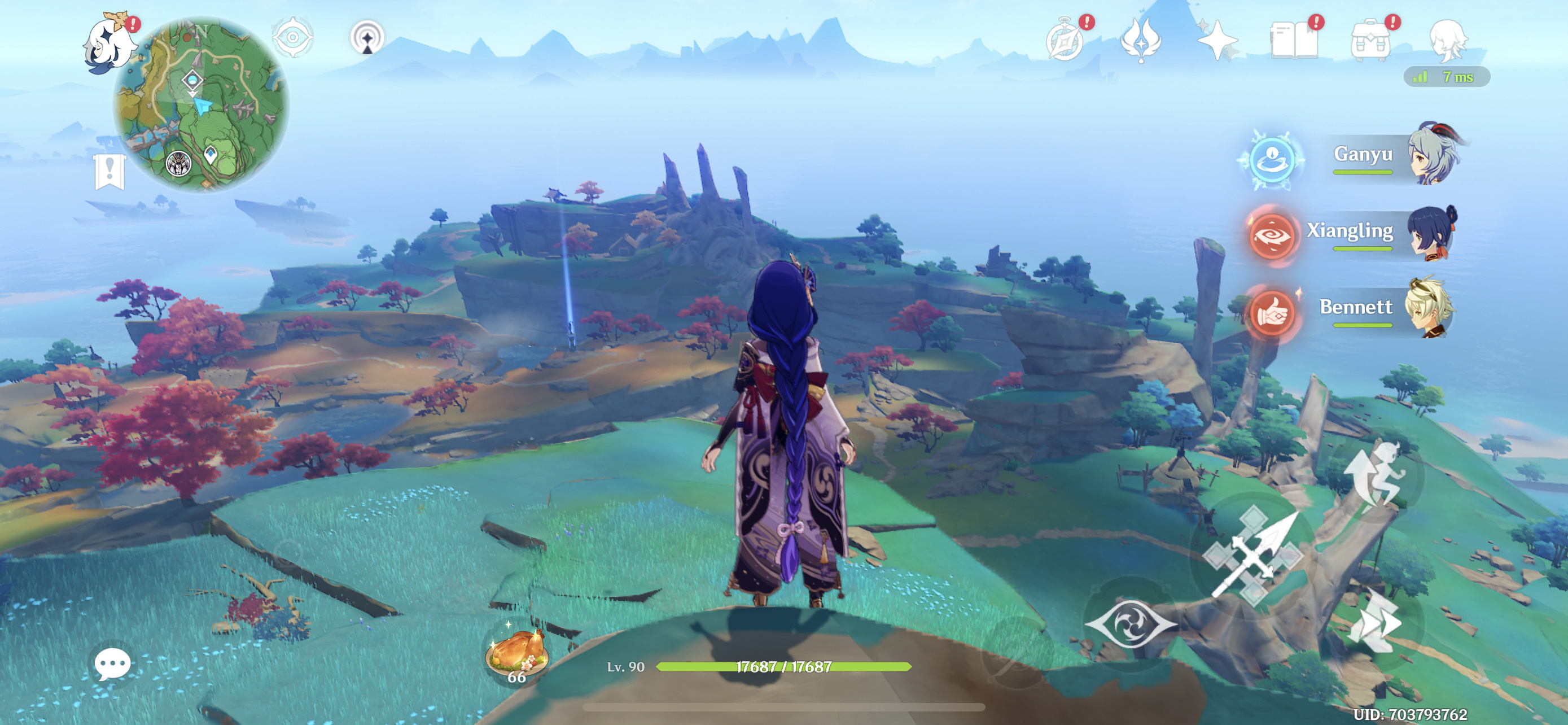
iPhone 13 Pro Max - A15
The comparison between Android phones and iPhones gets even more complicated in that even with the same game setting, the iPhones still have slightly higher resolution, and visual effects that are just outright missing from the Android variant of the game. The visual fidelity of the game is just much higher on Apple’s devices due to the superior shading and features.
In general, this is one reason while I’m apprehensive of publishing real game benchmarks as it’s just a false comparison and can lead to misleading conclusions. We use specifically designed benchmarks to achieve a “ground truth” in terms of performance, especially in the context of SoCs, GPUs, and architectures.
The A15 continues to cement Apple’s dominance in mobile gaming. We’re looking forward to the next-gen competition, especially RDNA-powered Exynos phones next year, but so far it looks like Apple has an extremely comfortable lead to not have to worry much.








204 Comments
View All Comments
michael2k - Monday, October 4, 2021 - link
There's been work to document and improve on out of order vs in order energy efficiency (roughly a 150% energy consumption with a CG-OoO, and 270% with normal OoO) :https://dl.acm.org/doi/pdf/10.1145/3151034
So there really is an energy efficiency benefit to 'in order'; out of order gives you a 73% performance boost but a 270% increase in energy consumption:
Performance:
https://zilles.cs.illinois.edu/papers/mcfarlin_asp...
Power:
https://stacks.stanford.edu/file/druid:bp863pb8596...
In other words, if Apple had an in-order design it would use even less power, but as I understand it they have never had an in-order design. Make lemonade out of lemons as it were.
eastcoast_pete - Monday, October 4, 2021 - link
I will take a look at the links you posted, but this is the first time I read about out-of-order execution being referred to as "lemon" vs. in-order. The out-of-order efficiency cores that Apple's SoC have had for a while now are generally a lot better on perf/W than in-order designs like the A55. And yes, a (much slower) in-order small core might consume less energy in absolute terms, but the performance per Watt is still significantly worse. Lastly, why would ARM design its big performance cores (A76/77/78, X2) as out-of-order, if in-order would make them so much more efficient?jospoortvliet - Tuesday, October 5, 2021 - link
Because they would be slower in absolute terms. In theory, all other things being equal, an in-order core should be more efficient than an out of order core. In practice, not everything is ever equal so just because apples small cores are so extremely efficient doesn't mean the theory is wrong.michael2k - Wednesday, October 6, 2021 - link
ARM can't hit the same performance using in-order, so if you need the performance you need to use an out-of-order design. In theory you could clock the in-order design faster, but the bottleneck isn't CPU performance but stalls when waiting on memory; with the out-of-order design the CPU can start working on a different chunk of instructions while still waiting on memory for the first chunk.It's essentially like having a left turn, forward, and right turn lane available, so that drivers can join different queues, vs all drivers forced to use a single lane for left, forward, and right. If the car turning left cannot move because of oncoming traffic, cars moving forward or right are blocked.
As for your question regarding perf/W, you can see four different A55s all have the same perf but different W:
https://www.anandtech.com/show/16983/the-apple-a15...
This tells us that there is more to CPU energy use than the CPU, if you also have to include memory, memory controllers, storage controllers, and storage into the equation since the CPU needs to access/power all those things just to operate. The D1200 has better p/W across all it's cores despite being otherwise similar to the E2100 at the low and mid end (both have A55 and A78 but the E2100 uses far more power for those two cores)
Ppietra - Tuesday, October 5, 2021 - link
the thing is Apple’s efficiency cores are clearly far more efficient than ARM’s efficiency cores in most workloads...Just because someone is not able to make an OoO design more efficient is not proof that any OoO will inevitably be less efficient
Andrei Frumusanu - Tuesday, October 5, 2021 - link
Discussions and papers like these about energy just on a core basis are basically irrelevant because you don't have a core in isolation, you have it within a SoC with power delivery and DRAM. The efficiency of the core here can be mostly overshadowed by the rest of the system; the Apple cores results here are extremely efficient not only because of the cores but because the whole system is incredibly efficient.Look at how Samsung massacres their A55 results, that's not because their implementation of the A55 is bad, it's because everything surrounding it is bad, and they're driving memory controllers and what not uselessly at higher power even though the active cores can't make use of any of it. It creates a gigantic overhead that massively overshadows the A55 cores.
name99 - Thursday, October 7, 2021 - link
You are correct but as always the devil is in the details.(a) What EXACTLY is the goal? In-order works if the goal is minimal energy at some MINIMAL level of performance. But if you require performance above a certain level, in-order simple can't deliver (or, more precisely, the contortions required plus the frequency needed make this a silly exercise).
For microcontroller levels of performance, in-order is fine. You can boost it to two-wide and still do well; you can augment it with some degree of speculation and still do OK, but that's about it. ARM imagined small cores as doing a certain minimal level of work; Apple imagined them doing a lot more, and Apple appears to (once again) have skated closer to where the puck was heading, not where it was.
(b) Now microcontrollers are not nothing. Apple has their own controller core, Chinook, that's used all over the place (their are dozens of them on an M1) controlling things like GPU, NPU, ISP, ... Chinook is AArch64, at least v8.3 (maybe updated). It may be an in-order core, two or even one-wide, no-one knows much about [what we do know is mainly what we can get from looking at the binary blobs of the firmware that runs on it].
Would it make sense for Apple to have a programmer visible core that was between Chinook and Blizzard? For example give Apple Watch two small cores (like today) and two "tiny" cores to handle everything but the UI? Maybe? Maybe not if the core power is simply not very much compared to everything else (always-on stuff, radios, display, sensors, ...)?
Or maybe give something like Airpods a tiny core?
(c) Take numbers for energy and performance for IO vs OoO with a massive grain of salt. There have been various traditional ways of doing things for years; but Apple has up-ended so much of that tradition, figuring out ways to get the performance value of OoO without paying nearly as much of the energy cost as people assumed.
It's not that Apple invented all this stuff from scratch, more that there was a pool of, say, 200 good ideas out there, but every paper assumed "baseline+my one good idea", only Apple saw the tremendous *synergy* available in combining them all in a single design.
We can see this payoff in the way that Apple's small cores get so much performance at such low energy cost compared to ARM's in-order orthodoxy cores. Apple just isn't paying much of an energy price for all its smarts.
And yes, the cost of all this is more transistors and more area. To which the only logical response is "so what? area and transistors are cheap!"
Nicon0s - Tuesday, October 5, 2021 - link
>I don't see how they can get even close to the efficiency cores in Apple's SoC.Very simple actually. By optimized/modifying a Cortex A76.
The latest A510 is very very small and this limit's the potential of such a core.
techconc - Monday, October 18, 2021 - link
>Very simple actually. By optimized/modifying a Cortex A76.LOL... That would take a hell of a lot of "optimization" and a bit of magic maybe. The A15 efficiency cores match the A76 in performance at about 1/4 the power.
Raqia - Monday, October 4, 2021 - link
Interesting that the extra core on the 13 Pro GPU doesn't seem to do add much performance much over the 13's 4 cores even when unthrottled, certainly not 20%. Perhaps the bottleneck has to do with memory bandwidth.