The Apple A15 SoC Performance Review: Faster & More Efficient
by Andrei Frumusanu on October 4, 2021 9:30 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- Apple A15
CPU ST Performance: Faster & More Efficient
Starting off with this year’s review of the A15, in order to have a deeper look at the CPU single-threaded performance and power efficiency, we’re migrating over to SPEC CPU 2017. While 2006 has served us well over the years and is still important and valid, 2017 is now better understood in terms of its microarchitectural aspects in its components, and becoming more relevant as we moved our desktop side coverage to the new suite some time ago.
One continuing issue with SPEC CPU 2017 is the Fortran subtests; due to a lacking compiler infrastructure both on iOS and Android, we’re skipping these components entirely for mobile devices. What this means also, is that the total aggregate scores presented here are not comparable to the full suite scores on other platforms, denoted by the (C/C++) subscript in the score descriptions.
As always, because we’re running completely custom harnesses and not submitting the scores officially to SPEC, we have to denote the results as “estimates”, although we have high confidence in the accuracy.
In terms of compiler settings, we’re continuing to employ simple -Ofast flags without further changes, to be able to get the best cross-platform comparisons possible. On the iOS side of things, we’re running on the newest XCode 13 build tools, while on Android we’re running the NDKr23 build tools.
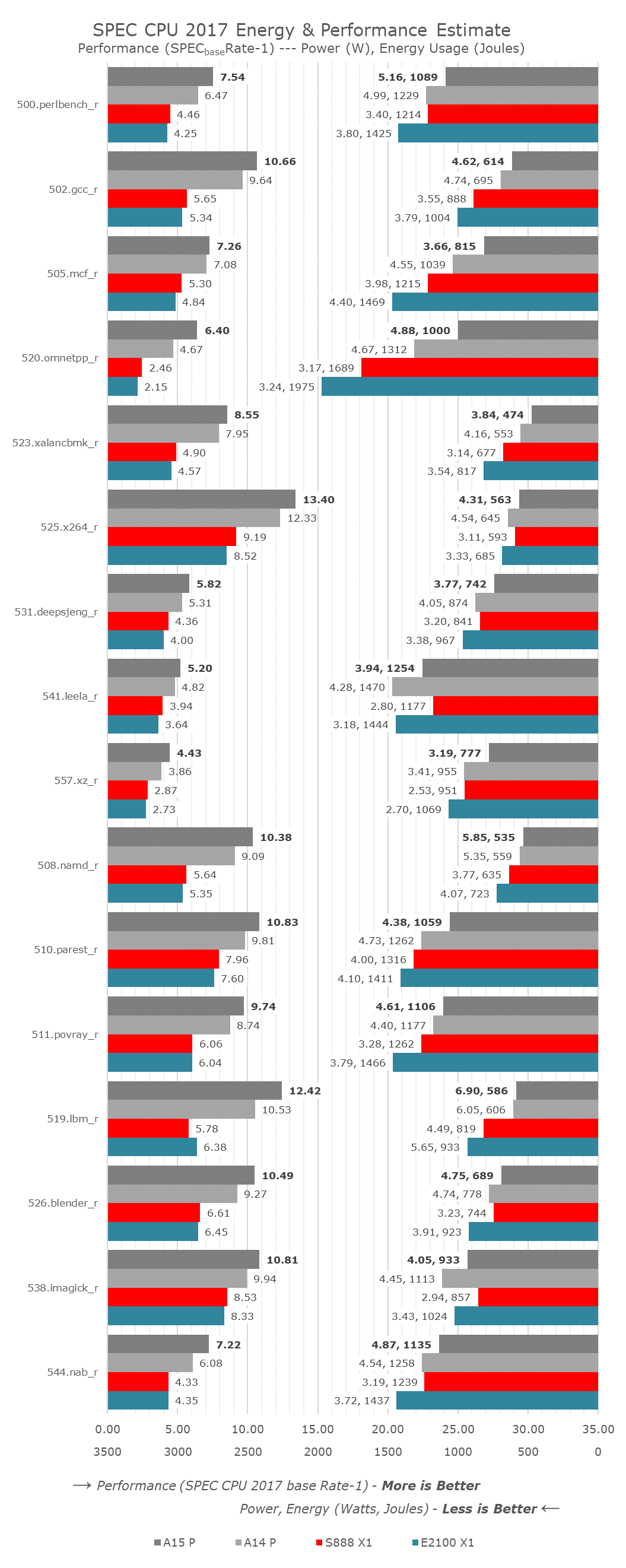
In terms of performance and efficiency details, we’re swapping the graphs around a bit from now on – on the left axis we have the performance scores of the tests – larger bars here mean better performance. On the right-side axis, growing from right to left are the energy consumption figures for the platforms, the smaller the figure, the more energy efficient (less energy consumed) a workload was completed. Alongside the energy figure in Joules, we’re also showcasing the average power figure in Watts.
Starting off with the performance figures of the A15, we’re seeing increases across the board, with absolute performance going up from a low of 2.5% to a peak of +37%.
The lowest performance increases were found in 505.mcf_r, a more memory latency sensitive workload; given the increased L2 latency as well as slightly higher DRAM latency, it doesn’t come too unexpected to see a more minor performance increase. However, when looking at the power and efficiency metrics of the same workload, we see the A15 use up almost 900mW less than the A14, with energy efficiency improving by +22%. 520.omnetpp_r saw the biggest individual increase at +37% performance – power here went up a bit, but energy efficiency is also up 24%.
The smallest performance gains of the A15 are found in the most back-end execution bound workloads, 525.x264_r and 538.imagick_r improve by only 8.7%, resulting in an IPC increase of 0.6% - essentially within the realm of measurement noise. Still, even here in this worst performance case, Apple still managed to improve energy efficiency by +13%, as the new chip is using less absolute power even though clock frequencies have gone up.
The most power demanding workload, 519.lbm_r, is extremely bandwidth hungry and stresses the DRAM the most in the suite, with the A15 chip here eating a whopping 6.9W of power. Still, energy efficiency is generationally slightly improved as performance goes up by 17.9% - based on first teardown reports, the A15 is still only powered by LPDDR4X-class memory, so these improvements must be due to the chip’s new memory subsystem and new SLC.
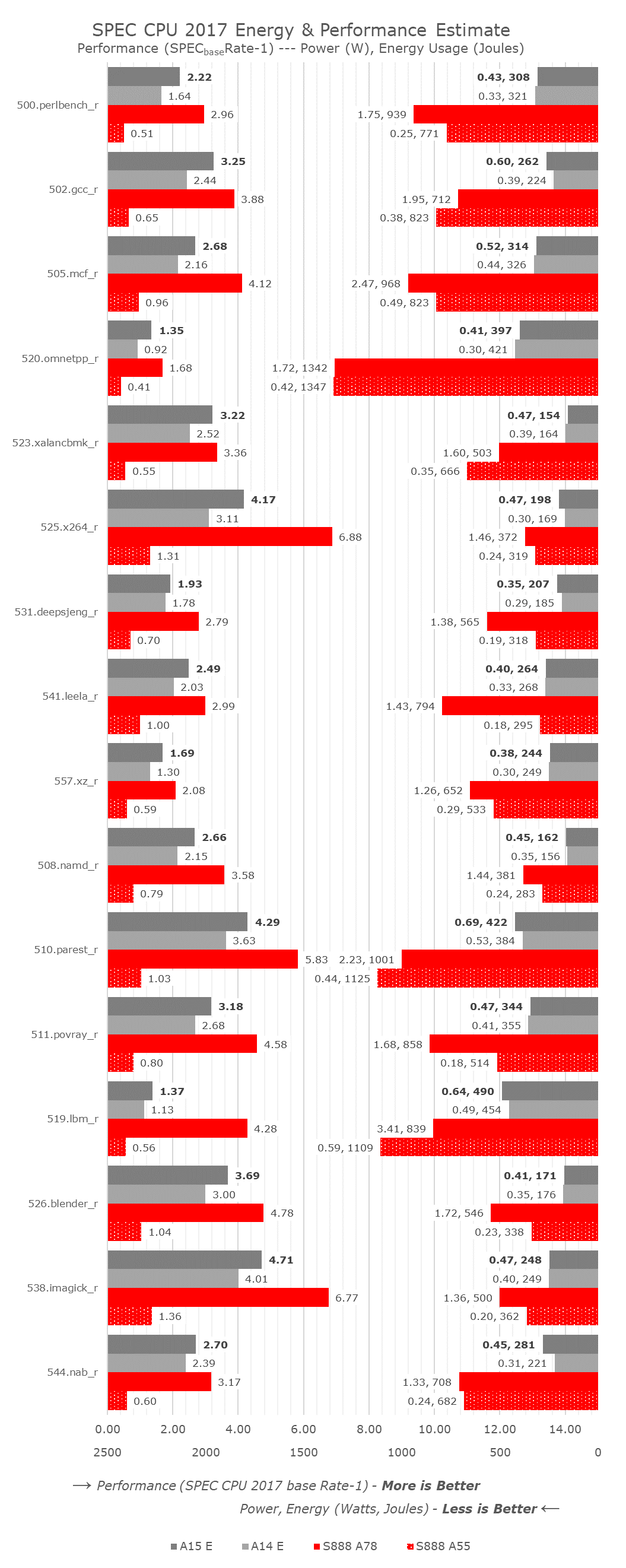
Shifting things over to the efficiency cores, I wanted to make comparisons not only to the A14’s E-cores, but also put the Apple chips in context to the competition, a Snapdragon 888 in this context, comparing against a 2.41GHz Cortex-A78 mid-core, as well as a 1.8GHz Cortex-A55 little core.
The A15’s E-cores are extremely impressive when it comes to performance. The minimum improvement varies from +8.4 in the 531.deepsjeng_r, essentially flat up with clocks, to up to again +46% in 520.omnetpp_r, putting more evidence into some sort of large effective sparse memory access parallelism improvement for the chip. The core has a median performance improvement of +23%, resulting in a median IPC increase of +11.6%. The cores here don’t showcase the same energy efficiency improvement as the new A15’s performance cores, as energy consumption is mostly flat due to performance increases coming at a cost of power increases, which are still very much low.
Compared to the Snapdragon 888, there’s quite a stark juxtaposition. First of all, Apple’s E-cores, although not quite as powerful as a middle core on Android SoCs, is still quite respectable and does somewhat come close to at least view them in a similar performance class. The comparison against the little Cortex-A55 cores is more absurd though, as the A15’s E-core is 3.5x faster on average, yet only consuming 32% more power, so energy efficiency is 60% better. Even for the middle cores, if we possibly were to down-clock them to match the A15’s E-core’s performance, the energy efficiency is multiple factors off what Apple is achieving.
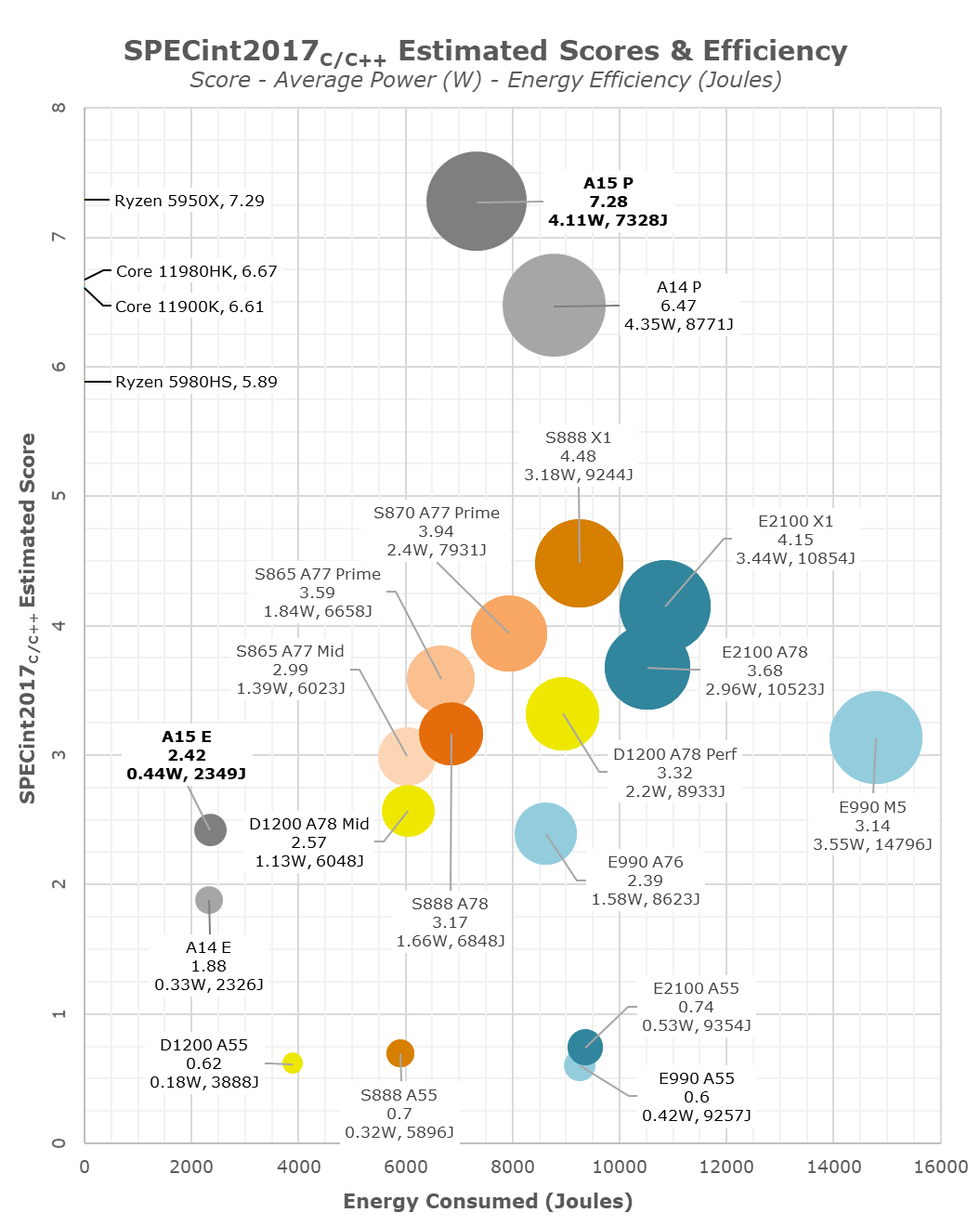
In the overview graph, I’m also changing things a bit, and moving to bubble charts to better spatially represent the performance to energy efficiency positioning, as well as the performance to power positioning. In the energy axis graphs, which I personally find to be more representative of the comparative efficiency and resulting battery life experiences of the SoCs, we see the various SoCs at their peak CPU performance states versus the total energy consumed to complete the workloads. On the power axis graphs, we see the same data, only plotted against average power. Generally, I find distinction of efficiency here to be quite harder between the various data-points, however some readers have requested this view. The bubble size corresponds to the average power of the various CPUs, we’re measuring system active power, meaning total device workload power minus idle power, to compensate components such as the display.
Apple A15 performance cores are extremely impressive here – usually increases in performance always come with some sort of deficit in efficiency, or at least flat efficiency. Apple here instead has managed to reduce power whilst increasing performance, meaning energy efficiency is improved by 17% on the peak performance states versus the A14. If we had been able to measure both SoCs at the same performance level, this efficiency advantage of the A15 would grow even larger. In our initial coverage of Apple’s announcement, we theorised that the company might possibly invested into energy efficiency rather than performance increases this year, and I’m glad to see that seemingly this is exactly what has happened, explaining some of the more conservative (at least for Apple) performance improvements.
On an adjacent note, with a score of 7.28 in the integer suite, Apple’s A15 P-core is on equal footing with AMD’s Zen3-based Ryzen 5950X with a score of 7.29, and ahead of M1 with a score of 6.66.
The A15’s efficiency cores are also massively impressive – at peak performance, efficiency is flat, but they’re also +28% faster. Again, if we would be able to compare both SoCs at the same performance level, the efficiency advantage of the A15’s E-cores would be very obvious. The much better performance of the E-cores also massively helps avoiding the P-cores, further improving energy efficiency of the SoC.
Compared to the competition, the A15 isn’t +50 faster as Apple claims, but rather +62% faster. While Apple’s larger cores are more power hungry, they’re still a lot more energy efficient. Granted, we are seeing a process node disparity in favour of Apple. The performance and efficiency of the A15 E-cores also put to shame the rest of the pack. The extremely competent performance of the 4 efficiency cores alongside the leading performance of the 2 big cores explain the significantly better multi-threaded performance than the 1+3+4 setups of the competition.
Overall, the new A15 CPUs are substantial improvements, even though that’s not immediately noticeable to some. The efficiency gains are likely key to the new vastly longer battery longevity of the iPhone 13 series phones – more on that in a dedicated piece in a few days, and in our full device review.








204 Comments
View All Comments
name99 - Monday, October 4, 2021 - link
You see it for GPU compute, eghttps://browser.geekbench.com/v5/compute/compare/3...
Unclear why you get even BETTER than 25% in that case (these were not cherry picked results)
Are there more differences than Apple has told us (like the Pro, ie 6GB, models, are using two DIMMs and have twice the bandwidth?)
As for whether game results or Compute results better reflect the SoC, well...
Obviously Apple is using all this GPU/NPU stuff in some places like computational photography, where people like it. The Siri image recognition stuff is definitely getting more valuable (I tried plant recognition this week and was pleasantly surprised, though the UI remains clumsy and sub-optimal). Likewise translation advances by fits and starts, though again hampered by lousy UI; likewise we'll see how well the Live Text stuff works (so far the one time I tried it, I was not impressed, but that was a very complex image so maybe I was hoping for too much).
All these smarts are definitely valuable and, for many users, probably more valuable than a CPU 50% faster.
On the other hand so many NPU-hooked up functions still seem so freaking dumb! Everyone hates the keyboard error correction stuff, things like choosing the appropriate contact when you have two with the same name seem to have zero intelligence behind them, I've even heard Maps Siri call a succession of streets of the form S Oak Ave "Sangrida Oak Ave". (N, W, E were correct. First time I had no idea what I heard so I listened carefully from that point on. All S were pronounced as something like Sangrida!)
it's unclear (to me anywhere) where this NPU-adjacent dumbness comes from. Poorly trained models? Not enough NPU on my hardware, so I should go out and get new hardware? Different Apple groups (especially teams like Contacts and Reminders) using the NNU API's incorrectly because they have no in-team AI experience and are just guessing at what they are doing?
cha0z_ - Tuesday, October 5, 2021 - link
Check the results again, it does provide decent uplift in peformance (peak), but apple decided to keep it at lower power figures in sustain performance and while doing so they achieve slightly higher performance vs the 4 core GPU. Instead of faster performance they decided to use the 5th GPU for lower power draw in thermally limited scenarios (sustained performance).name99 - Monday, October 4, 2021 - link
It's worth comparing the SPEC2017 results with https://www.anandtech.com/show/16252/mac-mini-appl... which gives the M1 results; the simple summary comparison hides a lot.In particular we can see that most of the int benchmarks are much the same; in other words not much apparent change in IPC, and now A15 matching M1's frequency. We do see a few minor M1 wins because it has a wider path to DRAM.
The interesting cases are the massive jumps -- omnetpp and xalanc. What's with those?
I'm not wild about the methodology in this paper:
https://dl.acm.org/doi/pdf/10.1145/3446200
but it does has a few interesting plots. Of particular relevance is Fig 4, which (look at the red triangles) gives us the working set size of the SPEC2017 programs.
Omnetpp is characterized as 64MB, but with enough locality (or the SoC doing a good job of detecting streaming data and not caching it) the difference between the previous cache space available and the current cache space may explain most of the boost.
The other big change is xalanc, and we see that its working set is right at 8MB. You could try to make an argument about caches, but I don't think that's right. Instead I'd urge you to compare the A15 result, the A14 result (which I am guessing, Andrei can confirm, was measured this run, using XCode 13), and the M1 result.
The value for A14 xalanc (and the rather less interesting x264) are notably higher, like ~10..15% higher. This suggests a compiler (or, harder to imagine, an OS) change -- most likely something like one apparently small tweak in a loop that now allows a scalar loop to be vectorized, or (less likely, but not impossible) that restructures the direction of memory traversal.
So I'd conclude that, in a way, we are ultimately back to where we were after the announcement and the first GB5 values!
- performance essentially tracking the frequency improvement
- for very particular pieces of code, which just happen to be larger than the pervious L2+SLC could capture, but which now fit into L2+SLC, a better than expected boost (only really relevant to omnetpp)
- for other very particular pieces of code which just happen to match the pattern, a nice boost from latest XCode (but not limited to just this CPU/SoC)
But no evidence of anything but the most minor IPC-relevant modifications to the P core. Energy mods, of course, always desirable, and probably necessary to make that frequency boost useful rather than a gimmick, but not IPC boosts.
It would be interesting if those who track these things were to report anything significant in code gen by the newest XCode. Last time I looked at this stuff (not quite a year ago)
- complex support was still in progress, with lousy use of the ARMv8 complex instructions (Some use, but far from optimal). I'd like to hope that's all fixed, but it seems unlikely to be relevant to xalanc.
- there was ongoing talk of compiler level support for matrices (not just AMX, but support for various TPUs, and for various matrix instructions being added across ISA's). Again, interesting and hopefully having made progress, but not relevant here.
- the usual never-ending "better support, clean up and restructure nested loops" and "better vectorized code", and those two seem the most likely candidates?
Andrei Frumusanu - Tuesday, October 5, 2021 - link
Please avoid using the M1 numbers here, those were on macOS and on a different compiler version.Xalanc is memory allocator sensitive and that's the major contributable to the M1 and A14 differences as iOS is running some sort of aggregator allocator similar to jemalloc.
The x264 differences are due to Xcode13 using a new LLVM 12 toolchain, Android NDKr23 had the same improvements, see : https://community.arm.com/developer/tools-software...
name99 - Tuesday, October 5, 2021 - link
Thanks for the memory allocator detail!But basically the point remains -- everything converges on essentially the same IPC (modulo larger L2 and SLC); just substantially improved energy.
Reason I went down this path was the *apparent* substantial jump between the M1 SPEC2017 numbers and the A15 numbers, which I wanted to resolve.
name99 - Monday, October 4, 2021 - link
"This year’s CPU microarchitectures were a bit of a wildcard. Earlier this year, Arm had announced the new Armv9 ISA, predominantly defined by the new SVE2 SIMD instruction set, as well as the company’s new Cortex series CPU IP which employs the new architecture. Back in 2013, Apple was notorious for being the first on the market with an Armv8 CPU, the first 64-bit capable mobile design. Given that context, I had generally expected this year’s generation to introduce v9 as well, but however that doesn’t seem to be the case for the A15."One thing we all forgot, or overlooked, was the announcement earlier this year of SME (Scalable Matrix Extension) which along with the other stuff it does, adds a wrinkle to SVE via the addition of SVE/2 Streaming Mode.
Is it possible that Apple has decided to (for the second time) delay implementing because these changes (addition of Streaming Mode and SME) change things sufficiently that you might as well design for them from the start?
There's obviously value in learning-by-doing, even if you can't ship the final product you want.
But there's also obvious value in trying to avoid fragmenting the ISA base as much as possible.
Is it possible that Apple have concluded (having fixed the immediate problems with v8 aggressively every year) that going forward a better model is more something like an ISA update every 4 or so years (and so fairly clearly differentiated classes of compiler target) rather than annual updates? Starting with delivering an SVE/SME that's fully featured (at least as of mid 2021) rather than two successive versions of SVE, the first without SME and SVE streaming?
ARM seems to have decided to hell with it, they're going to accept this ISA incompatibility and ship V1 with SVE, and N2 with SVE2-lite (ie no SME/streaming). Probably an acceptable choice given those are data center designs.
In Apple's world, ideally finalization of code within the App Store down to the precise CPU of each customer would solve this issue. But Apple may have concluded some combination of the legal fights around the App Store and perhaps real-world difficulty of debugging by devs under these circumstances where they can never be sure quite what binary each user has installed, have rendered this infeasible?
(Honestly I'd hope that the legal issues force things the other way, including forcing the App Store to provide more developer value by doing a much better job of constant app improvement -- both per-CPU finalization, and constant recompilation of older code with newer compilers, along with much better support for debugging help. Well, we'll see. Maybe, with the current rickety state of compiler trustworthiness, that vision is still too much to hope for?)
OreoCookie - Tuesday, October 5, 2021 - link
I think you are spot-on: I don’t think there would have been a similarly large payoff as compared with going from 32 bit to 64 bit. Given all the external parameters, pandemic, staff leaving, going with a tock cycle is a prudent choice. Especially if Apple not only undersold the improvements, but could have genuinely made more of a deal about them focussing on efficiency with this release. Given how much faster they are than their competition, I think focussing on efficiency is a good thing.Further, *if* Apple had decided on adopting a new instruction set, I would have expected to traces of that in the toolchain, e. g. in llvm.
name99 - Tuesday, October 5, 2021 - link
Yeah, the one thing one sees in the toolchain (eg Andrei's link above) https://community.arm.com/developer/tools-software...is just how immature SVE compiling still is.
I don't want to complain about that -- compilers are HARD! But releasing HW on the hope that the compiler will get there is a tough sell.
On the one hand, yes, it is harder for compiler devs 9and everyone else, like those who write specialized optimized assembly) to make progress without HW.
On the other hand, you only get one chance to make a first impression, and if you blow it with a fragmented ISA, a poor implementation, or unimpressive performance (*cough* AVX512 *cough*) it's hard to recover from that.
I guess Apple see little downside in having ARM bear the costs of being the pioneer this time round.
OreoCookie - Thursday, October 7, 2021 - link
Yes, the maturity of the toolchain is another major factor: part of Apple’s secret sauce is the tight integration of software and hardware. Its SoCs are designed to accelerate e. g. JavaScript and reference counting (https://twitter.com/Catfish_Man/status/13262384342...Another thing is that at least for some of the new capabilities that SVE brings are probably — at least in part — covered by other specialized hardware on Apple’s SoCs.
PS AVX512 pipelines are also massively power hungry, so that’s another trade-off to consider.
williwgtr - Tuesday, October 5, 2021 - link
It may be faster but what good is that if you want to play 20 minutes you can not low FPS, the CPU setting is aggressive to prevent it from getting hot