The Apple A15 SoC Performance Review: Faster & More Efficient
by Andrei Frumusanu on October 4, 2021 9:30 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- Apple A15
GPU Performance - Great GPU, So-So Thermals Designs
The GPUs on the A15 iPhones are interesting, this is the first time that Apple has functionally segmented the GPU configurations on their SoCs within the iPhone device range, with the iPhone 13 mini and iPhone 13 receiving a 4-core GPU, similar to the A14 devices last year, while the 13 Pro and 13 Pro Max receive a 5-core variant of the SoC. It’s still the same SoC and silicon chip in both cases, just that Apple is disabling one GPU core on the non-Pro models, possibly for yield reasons?
Apple’s performance figures for the GPU were also a bit intriguing in that there weren’t any generational comparisons, just a “+30%” and “+50%” figure against the competition. I initially theorized to mean +10% and +28% against the A14, so let’s see if that pans out:
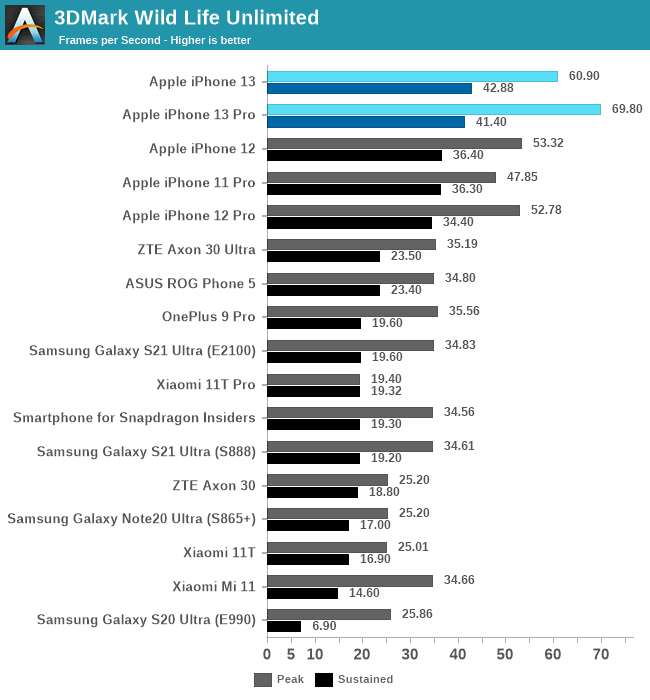
In the 3DMark Wild Life test, we see the 5-core A15 leap the A15 by +30%, while the 4-core showcases a +14% improvement, so quite close to what we predicted. The peak performance here is essentially double that of the nearest competitor, so Apple is likely low-balling things again.
In terms of sustained performance, the new chips continue to showcase a large difference in what they achieve with a cold phone versus a heated phone, interestingly, the 4-core iPhone 13 lands a bit ahead of the 13 Pro here, more on this later.
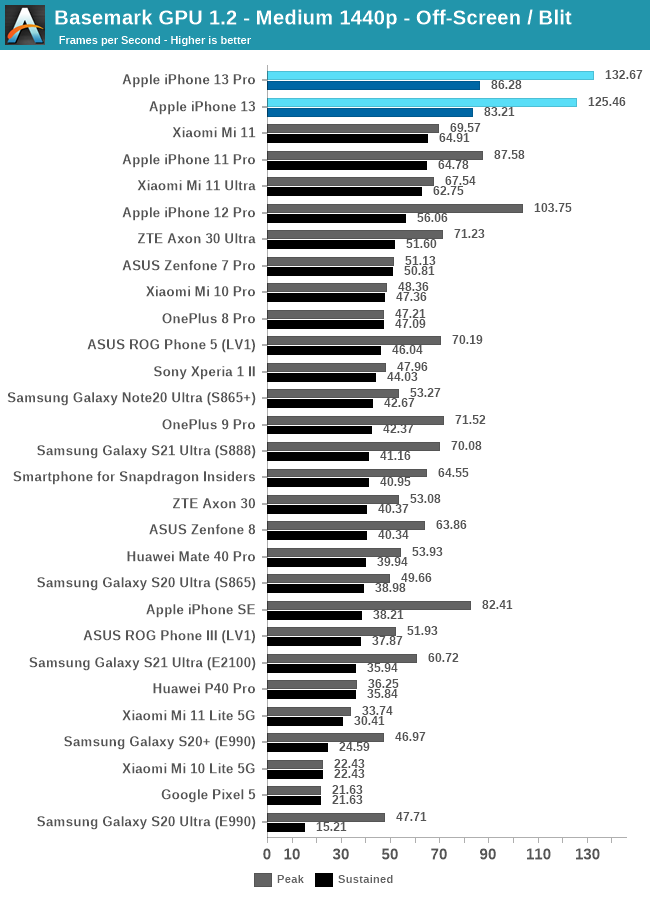
In Basemark GPU, the 13 Pro lands in at +28% over the 12 Pro, with the 4-core iPhone 13 only being slightly slower. Again, the phones throttle hard, however still manage to land with sustained performances well above the peak performances of the competition.
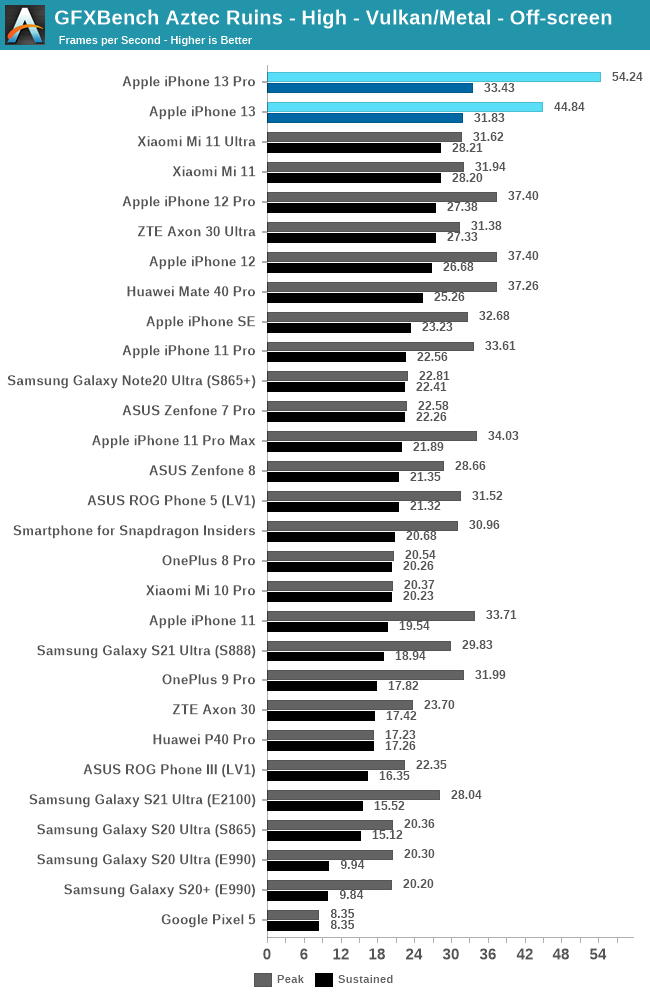
In GFXBench Aztec High, the 13 Pro lands in at a massive +46% performance advantage over the 12 Pro, while the 13 showcases a +19% boost. These are numbers that are above the expectations – in terms of microarchitectural changes the new A15 GPU appears to adopt the same double FP32 throughput as on the M1 GPU, seemingly adding extra units alongside the existing FP32/double-rate FP16 ALUs. The increased 32MB SLC will also likely help a lot with GPU bandwidth and hit-rates, so these two changes seem to be the most obvious explanations for the massive increases.
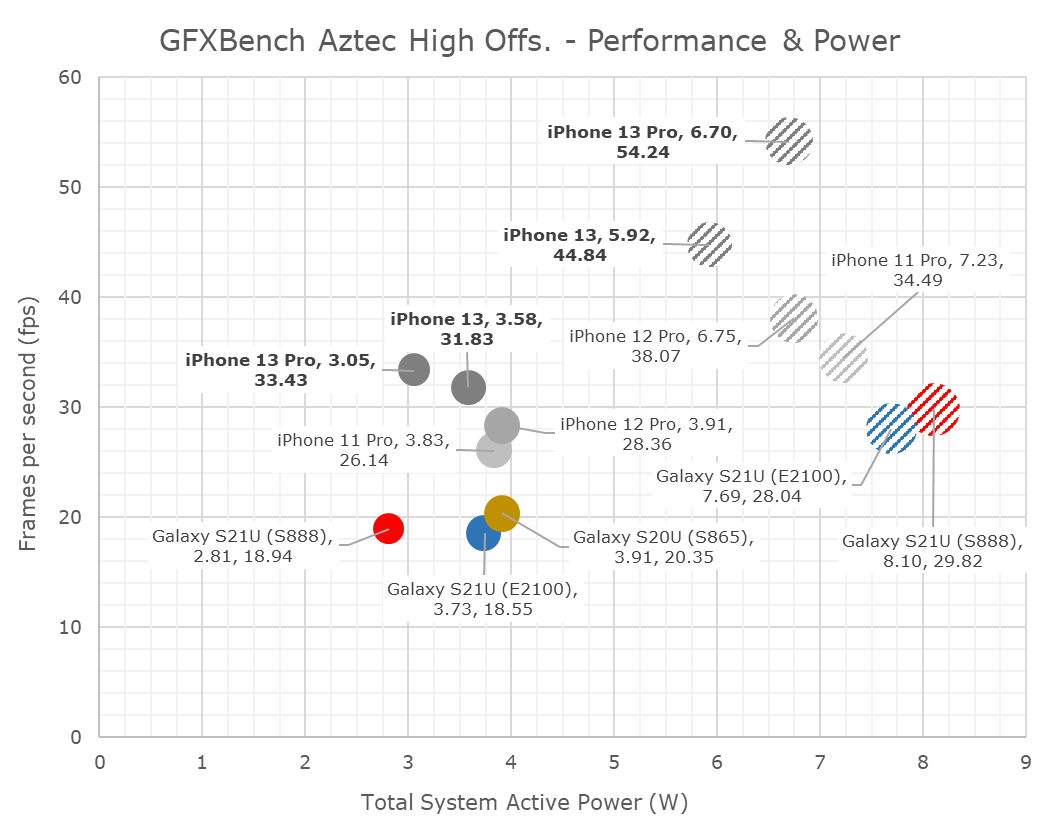
In terms of power and efficiency, I’m also migrating away from tables to bubble charts to better represent the spatial positioning of the various SoCs.
I’d also like to note here that I had went ahead and re-measured the A13 and A14 phones in their peak performance states, showcasing larger power figures than the ones we’ve published in the past. Reason for this is the methodology where we’re only able to measure via input power of the phone, as we cannot dismantle our samples and are lacking PMIC fuelgauge access otherwise. The iPhone 13 figures here are generally hopefully correct as I measured other scenarios up to 9W, however there is still a bit of doubt on whether the phone is drawing from battery or not. The sustained power figures have a higher reliability.
As noted, the A15’s peak performance is massively better, but also appearing that the phone is improving the power draw slightly compared to the A14, meaning we see large efficiency improvements.
Both the 13 and 13 Pro throttle quite quickly after a few minutes of load, but generally at different power points. The 13 Pro with its 5-core GPU throttles down to around 3W, while the 13 goes to around 3.6W.
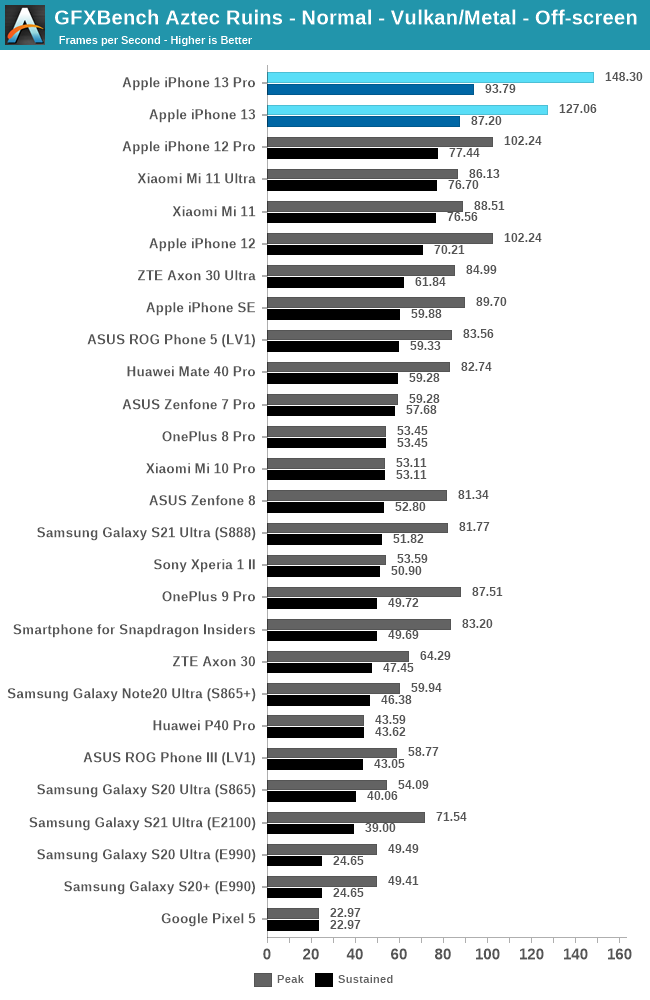
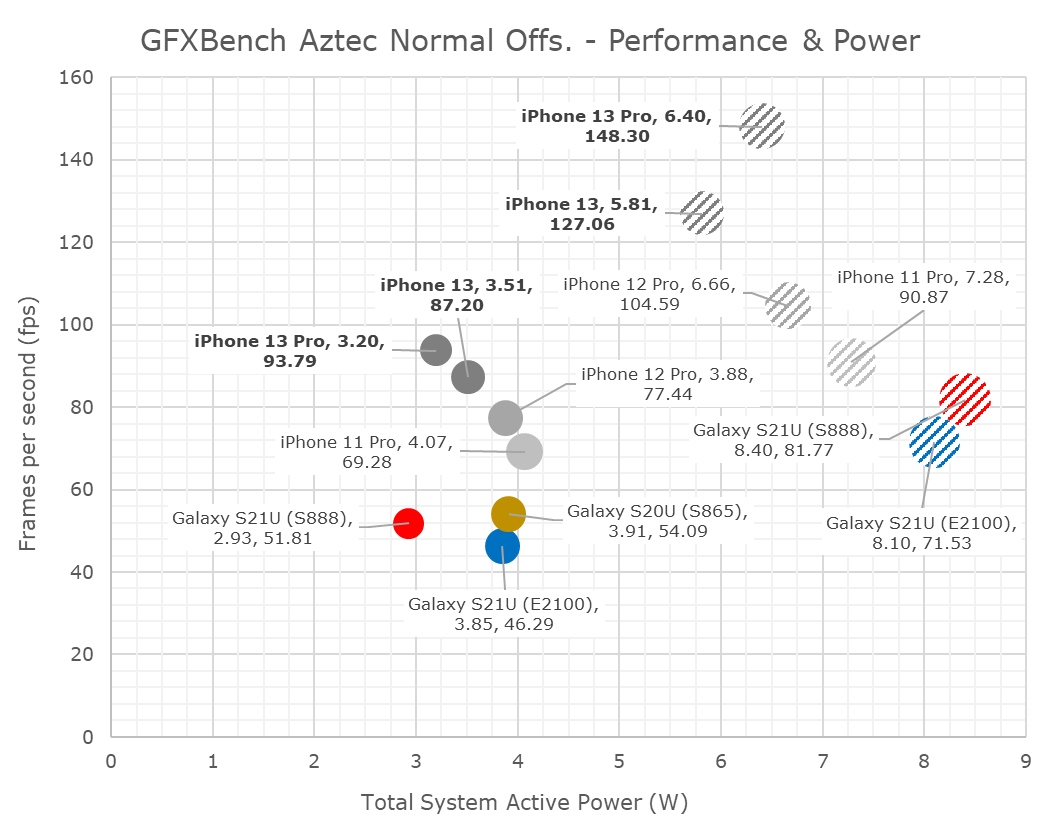
In Aztec Normal, we’re seeing similar relative positioning both in performance and efficiency. The iPhones 13 and 13 Pro are quite closer in performance than expected, due to different throttling levels.
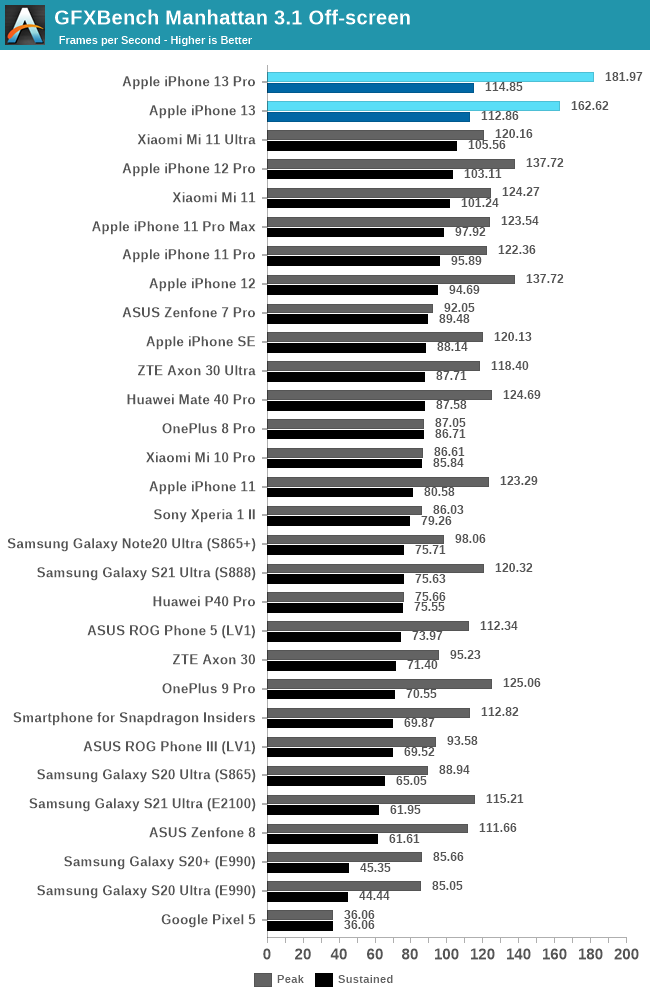
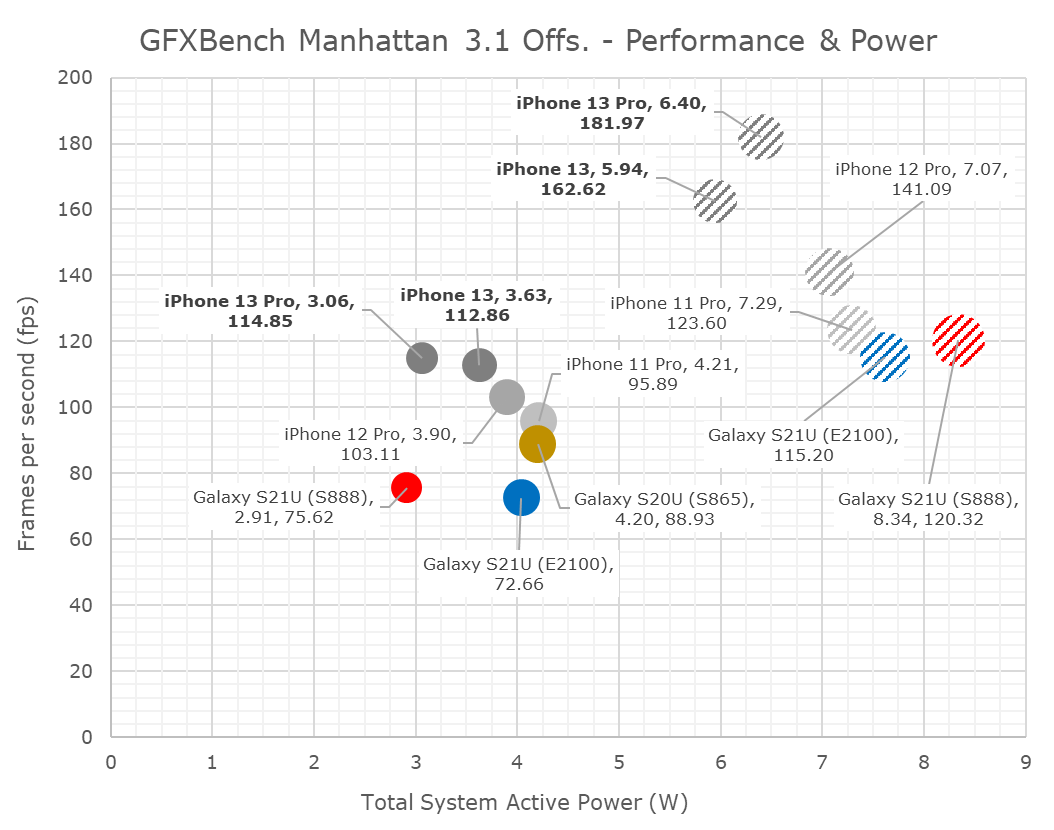
Finally, in Manhattan 3.1, the A15’s 5-core goes up +32%, while the 4-core goes up +18%. The sustained performance isn’t notably different between the two, and also represent smaller improvements over the iPhone 11 and 12 series.
Impressive GPU Performance, but quite limited thermals
Our results here showcase two sides of a coin: In terms of peak performance, the new A15 GPU is absolutely astonishing, and showcasing again improvements that are well above Apple’s marketing claims. The new GPU architecture, and possibly the new SLC allow for fantastic gains in performance, as well as efficiency.
What’s not so great, is the phone’s throttling. Particularly, we seem to be seeing quite reduced power levels on the iPhone 13 Pro, compared to the iPhone 13 as well as previous generation iPhones.


Source: 微机分WekiHome
The 13 Pro models this year come with a new PCB design, that’s even denser than what we’ve had on the previous generations, in order to facilitate the larger battery and new camera modules. What’s been extremely perplexing with Apple’s motherboard designs has been the fact that since they employed dual-layer “sandwich” PCBs, is that they’re packaging the SoC on the inside of the two soldered boards. This comes in contrast to other vendors such as Samsung, who also have adopted the “sandwich” PCB, but the SoC is located on the outer side of the assembly, making direct contact with the heat spreader and display mid-frame.
There are reports of the new iPhones throttling more under gaming and cellular connectivity – well, I’m sure that having the modem directly opposite the SoC inside the sandwich is a contributor to this situation. The iPhone 13 Pro showcasing lower sustained power levels may be tied to the new PCB design, and Apple’s overall iPhone thermal design is definitely amongst the worst out there, as it doesn’t do a good job of spreading the heat throughout the body of the phone, achieving a SoC thermal envelope that’s far smaller than the actual device thermal envelope.
No Apples to Apples in Gaming
In terms of general gaming performance, I’ll also want to make note of a few things – the new iPhones, even with their somewhat limited thermal capacity, are still vastly faster than give out a better gaming experience than competitive phones. Lately benchmarking actual games has been something that has risen in popularity, and generally, I’m all for that, however there are just some fundamental inconsistencies that make direct game comparisons not empirically viable to come to SoC conclusions.
Take Genshin Impact for example, unarguably the #1 AAA mobile game out there, and also one of the most performance demanding titles in the market right now, comparing the visual fidelity on a Galaxy S21 Ultra (Snapdragon 888), Mi 11 Ultra, and the iPhone 13 Pro Max:
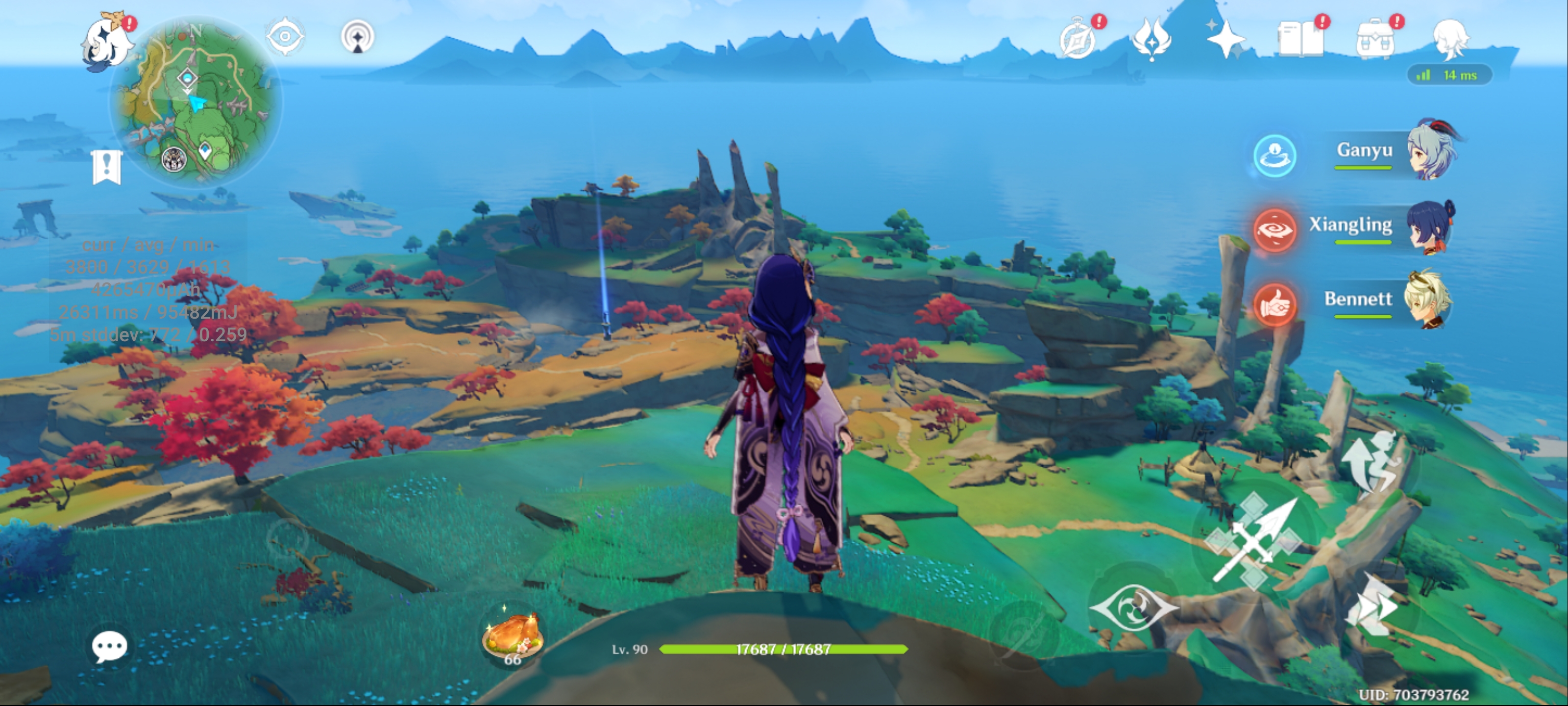
Galaxy S21 Ultra - Snapdragon 888

Mi 11 Ultra - Snapdragon 888
Even though the S21 Ultra and the Mi 11 Ultra both feature the same SoC, they have very different characteristics in terms of thermals. The S21 Ultra generally sustains about 3.5W total device power under the same conditions, while the Mi 11 Ultra will hover between 5-6W, and a much hotter phone. The difference between the two not only exhibits itself in the performance of the game, but also in the visual fidelity, as the S21 Ultra is running much lower resolution due to the game having a dynamic resolution scaling (both phones had the exact same game settings).
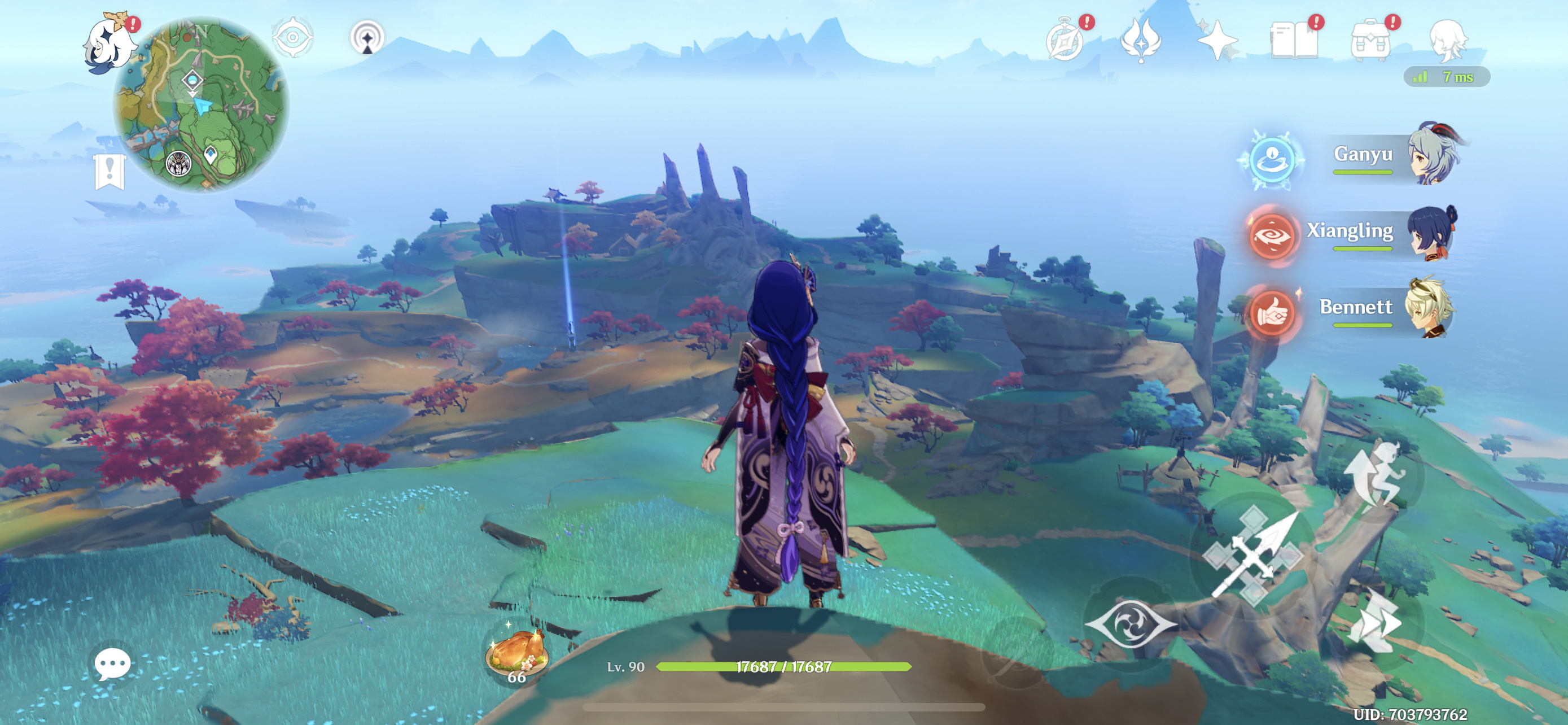
iPhone 13 Pro Max - A15
The comparison between Android phones and iPhones gets even more complicated in that even with the same game setting, the iPhones still have slightly higher resolution, and visual effects that are just outright missing from the Android variant of the game. The visual fidelity of the game is just much higher on Apple’s devices due to the superior shading and features.
In general, this is one reason while I’m apprehensive of publishing real game benchmarks as it’s just a false comparison and can lead to misleading conclusions. We use specifically designed benchmarks to achieve a “ground truth” in terms of performance, especially in the context of SoCs, GPUs, and architectures.
The A15 continues to cement Apple’s dominance in mobile gaming. We’re looking forward to the next-gen competition, especially RDNA-powered Exynos phones next year, but so far it looks like Apple has an extremely comfortable lead to not have to worry much.








204 Comments
View All Comments
name99 - Monday, October 4, 2021 - link
You see it for GPU compute, eghttps://browser.geekbench.com/v5/compute/compare/3...
Unclear why you get even BETTER than 25% in that case (these were not cherry picked results)
Are there more differences than Apple has told us (like the Pro, ie 6GB, models, are using two DIMMs and have twice the bandwidth?)
As for whether game results or Compute results better reflect the SoC, well...
Obviously Apple is using all this GPU/NPU stuff in some places like computational photography, where people like it. The Siri image recognition stuff is definitely getting more valuable (I tried plant recognition this week and was pleasantly surprised, though the UI remains clumsy and sub-optimal). Likewise translation advances by fits and starts, though again hampered by lousy UI; likewise we'll see how well the Live Text stuff works (so far the one time I tried it, I was not impressed, but that was a very complex image so maybe I was hoping for too much).
All these smarts are definitely valuable and, for many users, probably more valuable than a CPU 50% faster.
On the other hand so many NPU-hooked up functions still seem so freaking dumb! Everyone hates the keyboard error correction stuff, things like choosing the appropriate contact when you have two with the same name seem to have zero intelligence behind them, I've even heard Maps Siri call a succession of streets of the form S Oak Ave "Sangrida Oak Ave". (N, W, E were correct. First time I had no idea what I heard so I listened carefully from that point on. All S were pronounced as something like Sangrida!)
it's unclear (to me anywhere) where this NPU-adjacent dumbness comes from. Poorly trained models? Not enough NPU on my hardware, so I should go out and get new hardware? Different Apple groups (especially teams like Contacts and Reminders) using the NNU API's incorrectly because they have no in-team AI experience and are just guessing at what they are doing?
cha0z_ - Tuesday, October 5, 2021 - link
Check the results again, it does provide decent uplift in peformance (peak), but apple decided to keep it at lower power figures in sustain performance and while doing so they achieve slightly higher performance vs the 4 core GPU. Instead of faster performance they decided to use the 5th GPU for lower power draw in thermally limited scenarios (sustained performance).name99 - Monday, October 4, 2021 - link
It's worth comparing the SPEC2017 results with https://www.anandtech.com/show/16252/mac-mini-appl... which gives the M1 results; the simple summary comparison hides a lot.In particular we can see that most of the int benchmarks are much the same; in other words not much apparent change in IPC, and now A15 matching M1's frequency. We do see a few minor M1 wins because it has a wider path to DRAM.
The interesting cases are the massive jumps -- omnetpp and xalanc. What's with those?
I'm not wild about the methodology in this paper:
https://dl.acm.org/doi/pdf/10.1145/3446200
but it does has a few interesting plots. Of particular relevance is Fig 4, which (look at the red triangles) gives us the working set size of the SPEC2017 programs.
Omnetpp is characterized as 64MB, but with enough locality (or the SoC doing a good job of detecting streaming data and not caching it) the difference between the previous cache space available and the current cache space may explain most of the boost.
The other big change is xalanc, and we see that its working set is right at 8MB. You could try to make an argument about caches, but I don't think that's right. Instead I'd urge you to compare the A15 result, the A14 result (which I am guessing, Andrei can confirm, was measured this run, using XCode 13), and the M1 result.
The value for A14 xalanc (and the rather less interesting x264) are notably higher, like ~10..15% higher. This suggests a compiler (or, harder to imagine, an OS) change -- most likely something like one apparently small tweak in a loop that now allows a scalar loop to be vectorized, or (less likely, but not impossible) that restructures the direction of memory traversal.
So I'd conclude that, in a way, we are ultimately back to where we were after the announcement and the first GB5 values!
- performance essentially tracking the frequency improvement
- for very particular pieces of code, which just happen to be larger than the pervious L2+SLC could capture, but which now fit into L2+SLC, a better than expected boost (only really relevant to omnetpp)
- for other very particular pieces of code which just happen to match the pattern, a nice boost from latest XCode (but not limited to just this CPU/SoC)
But no evidence of anything but the most minor IPC-relevant modifications to the P core. Energy mods, of course, always desirable, and probably necessary to make that frequency boost useful rather than a gimmick, but not IPC boosts.
It would be interesting if those who track these things were to report anything significant in code gen by the newest XCode. Last time I looked at this stuff (not quite a year ago)
- complex support was still in progress, with lousy use of the ARMv8 complex instructions (Some use, but far from optimal). I'd like to hope that's all fixed, but it seems unlikely to be relevant to xalanc.
- there was ongoing talk of compiler level support for matrices (not just AMX, but support for various TPUs, and for various matrix instructions being added across ISA's). Again, interesting and hopefully having made progress, but not relevant here.
- the usual never-ending "better support, clean up and restructure nested loops" and "better vectorized code", and those two seem the most likely candidates?
Andrei Frumusanu - Tuesday, October 5, 2021 - link
Please avoid using the M1 numbers here, those were on macOS and on a different compiler version.Xalanc is memory allocator sensitive and that's the major contributable to the M1 and A14 differences as iOS is running some sort of aggregator allocator similar to jemalloc.
The x264 differences are due to Xcode13 using a new LLVM 12 toolchain, Android NDKr23 had the same improvements, see : https://community.arm.com/developer/tools-software...
name99 - Tuesday, October 5, 2021 - link
Thanks for the memory allocator detail!But basically the point remains -- everything converges on essentially the same IPC (modulo larger L2 and SLC); just substantially improved energy.
Reason I went down this path was the *apparent* substantial jump between the M1 SPEC2017 numbers and the A15 numbers, which I wanted to resolve.
name99 - Monday, October 4, 2021 - link
"This year’s CPU microarchitectures were a bit of a wildcard. Earlier this year, Arm had announced the new Armv9 ISA, predominantly defined by the new SVE2 SIMD instruction set, as well as the company’s new Cortex series CPU IP which employs the new architecture. Back in 2013, Apple was notorious for being the first on the market with an Armv8 CPU, the first 64-bit capable mobile design. Given that context, I had generally expected this year’s generation to introduce v9 as well, but however that doesn’t seem to be the case for the A15."One thing we all forgot, or overlooked, was the announcement earlier this year of SME (Scalable Matrix Extension) which along with the other stuff it does, adds a wrinkle to SVE via the addition of SVE/2 Streaming Mode.
Is it possible that Apple has decided to (for the second time) delay implementing because these changes (addition of Streaming Mode and SME) change things sufficiently that you might as well design for them from the start?
There's obviously value in learning-by-doing, even if you can't ship the final product you want.
But there's also obvious value in trying to avoid fragmenting the ISA base as much as possible.
Is it possible that Apple have concluded (having fixed the immediate problems with v8 aggressively every year) that going forward a better model is more something like an ISA update every 4 or so years (and so fairly clearly differentiated classes of compiler target) rather than annual updates? Starting with delivering an SVE/SME that's fully featured (at least as of mid 2021) rather than two successive versions of SVE, the first without SME and SVE streaming?
ARM seems to have decided to hell with it, they're going to accept this ISA incompatibility and ship V1 with SVE, and N2 with SVE2-lite (ie no SME/streaming). Probably an acceptable choice given those are data center designs.
In Apple's world, ideally finalization of code within the App Store down to the precise CPU of each customer would solve this issue. But Apple may have concluded some combination of the legal fights around the App Store and perhaps real-world difficulty of debugging by devs under these circumstances where they can never be sure quite what binary each user has installed, have rendered this infeasible?
(Honestly I'd hope that the legal issues force things the other way, including forcing the App Store to provide more developer value by doing a much better job of constant app improvement -- both per-CPU finalization, and constant recompilation of older code with newer compilers, along with much better support for debugging help. Well, we'll see. Maybe, with the current rickety state of compiler trustworthiness, that vision is still too much to hope for?)
OreoCookie - Tuesday, October 5, 2021 - link
I think you are spot-on: I don’t think there would have been a similarly large payoff as compared with going from 32 bit to 64 bit. Given all the external parameters, pandemic, staff leaving, going with a tock cycle is a prudent choice. Especially if Apple not only undersold the improvements, but could have genuinely made more of a deal about them focussing on efficiency with this release. Given how much faster they are than their competition, I think focussing on efficiency is a good thing.Further, *if* Apple had decided on adopting a new instruction set, I would have expected to traces of that in the toolchain, e. g. in llvm.
name99 - Tuesday, October 5, 2021 - link
Yeah, the one thing one sees in the toolchain (eg Andrei's link above) https://community.arm.com/developer/tools-software...is just how immature SVE compiling still is.
I don't want to complain about that -- compilers are HARD! But releasing HW on the hope that the compiler will get there is a tough sell.
On the one hand, yes, it is harder for compiler devs 9and everyone else, like those who write specialized optimized assembly) to make progress without HW.
On the other hand, you only get one chance to make a first impression, and if you blow it with a fragmented ISA, a poor implementation, or unimpressive performance (*cough* AVX512 *cough*) it's hard to recover from that.
I guess Apple see little downside in having ARM bear the costs of being the pioneer this time round.
OreoCookie - Thursday, October 7, 2021 - link
Yes, the maturity of the toolchain is another major factor: part of Apple’s secret sauce is the tight integration of software and hardware. Its SoCs are designed to accelerate e. g. JavaScript and reference counting (https://twitter.com/Catfish_Man/status/13262384342...Another thing is that at least for some of the new capabilities that SVE brings are probably — at least in part — covered by other specialized hardware on Apple’s SoCs.
PS AVX512 pipelines are also massively power hungry, so that’s another trade-off to consider.
williwgtr - Tuesday, October 5, 2021 - link
It may be faster but what good is that if you want to play 20 minutes you can not low FPS, the CPU setting is aggressive to prevent it from getting hot