Qualcomm Announces Snapdragon 8 Gen 1: Flagship SoC for 2022 Devices
by Andrei Frumusanu on November 30, 2021 6:00 PM EST
At this year’s Tech Summit from Hawaii, it’s time again for Qualcomm to unveil and detail the company’s most important launch of the year, showcasing the newest Snapdragon flagship SoC that will be powering our upcoming 2022 devices. Today, as the first of a few announcements at the event, Qualcomm is announcing the new Snapdragon 8 Gen 1, the direct follow-up to last year’s Snapdragon 888.
The Snapdragon 8 Gen 1 follows up its predecessors with a very obvious change in marketing and product naming, as the company is attempting to simplify its product naming and line-up. Still part of the “8 series”, meaning the highest end segment for devices, the 8 Gen 1 resets the previous three-digit naming scheme in favor of just a segment and generation number. For Qualcomm's flagship part this is pretty straightforward, but it remains to be seen what this means for the 7 and 6 series, both of which have upwards of several parts for each generation.
As for the Snapdragon 8 Gen 1, the new chip comes with a lot of new IP: We’re seeing the new trio of Armv9 Cortex CPU cores from Arm, a whole new next-generation Adreno GPU, a massively improved imaging pipeline with lots of new features, an upgraded Hexagon NPU/DSP, integrated X65 5G modem, and all manufactured on a newer Samsung 4nm process node.
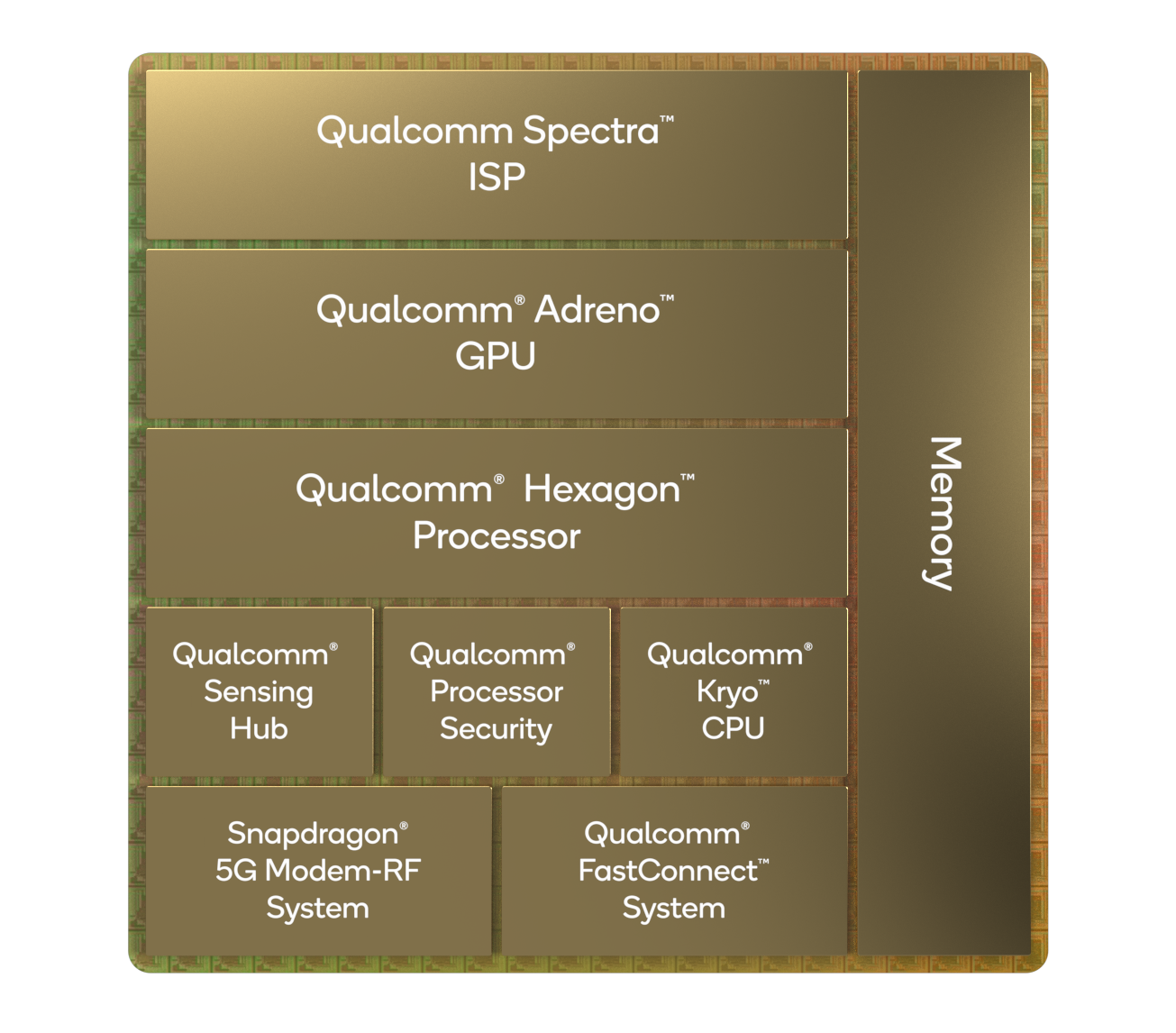
The new chip promises large increases in performance and efficiency in a lot of the processing elements, as well as new features enabling new user experiences. Let’s start over the basic specifications and drill down the details that we have on the chip:
| Qualcomm Snapdragon Flagship SoCs 2020-2021 | |||
| SoC |
Snapdragon 8 Gen 1 |
Snapdragon 888 | |
| CPU | 1x Cortex-X2 @ 3.0GHz 1x1024KB pL2 3x Cortex-A710 @ 2.5GHz 3x512KB pL2 4x Cortex-A510 @ 1.80GHz 2x??KB sL2 6MB sL3 |
1x Cortex-X1 @ 2.84GHz 1x1024KB pL2 3x Cortex-A78 @ 2.42GHz 3x512KB pL2 4x Cortex-A55 @ 1.80GHz 4x128KB pL2 4MB sL3 |
|
| GPU | Adreno next-gen | Adreno 660 @ 840MHz | |
| DSP / NPU | Hexagon | Hexagon 780 26 TOPS AI (Total CPU+GPU+HVX+Tensor) |
|
| Memory Controller |
4x 16-bit CH @ 3200MHz LPDDR5 / 51.2GB/s 4MB system level cache |
||
| ISP/Camera | Triple 18-bit Spectra ISP 1x 200MP or 108MP with ZSL or 64+36MP with ZSL or 3x 36MP with ZSL 8K HDR video & 64MP burst capture |
Triple 14-bit Spectra 580 ISP 1x 200MP or 84MP with ZSL or 64+25MP with ZSL or 3x 28MP with ZSL 4K video & 64MP burst capture |
|
| Encode/ Decode |
8K30 / 4K120 10-bit H.265 Dolby Vision, HDR10+, HDR10, HLG 720p960 infinite recording |
||
| Integrated Modem | X65 integrated (5G NR Sub-6 + mmWave) DL = 10000 Mbps UL = 3000 Mbps |
X60 integrated (5G NR Sub-6 + mmWave) DL = 7500 Mbps UL = 3000 Mbps |
|
| Mfc. Process | Samsung 4nm (unspecified) |
Samsung 5nm (5LPE) |
|
CPUs: Cortex-X2 and Armv9 siblings
Starting off with the CPUs of the new Snapdragon 8 Gen 1 (I’ll shorthand it as S8g1 here and there): This is Qualcomm’s first chip featuring the new Armv9 generation of CPU IPs from Arm, which includes the Cortex-X2, Cortex-A710, and Cortex-A510 in a big, middle, and little setup. Qualcomm continues to use a 1+3+4 core count, a setup that’s been relatively successful for the designers over the past few years and iterations ever since the Snapdragon 855.
The Cortex-X2 core of the new chip clocks in at 3.0GHz, which is a tad higher than the 2.84GHz clock of the X1 core on the Snapdragon 888. This was actually a bit surprising to me, as I hadn’t expected much in the way of clock increases this generation, but it’s nice to see Arm vendors now routinely achieving this. For context, MediaTek’s recently announced Dimensity 9000 achieves 3.05GHz on its X2 core, however that’s on a TSMC N4 node. In contrast, Qualcomm manufactures the Snapdragon 8 Gen 1 on a Samsung 4nm node. The company wouldn’t confirm if it’s a 4LPE variant or something more custom, hence why we’re leaving it as a “4nm” node description in the specification table.
What is most surprising about the X2 core is that Qualcomm is claiming 20% faster performance or 30% power savings, the latter figure being especially intriguing. Samsung Foundry only describe a 16% reduction in power in going from a 5nm to 4nm node, and obviously 30% is significantly better than what the process node promises. We asked Qualcomm what kind of improvements lead to such a large power decrease; however, the company wouldn’t specify any details. I particularly asked if the new X2 cores have their own voltage domain (Previous Snapdragon 1+3 big+middle implementations shared the same voltage rail), but the company wouldn’t even confirm if this was the case or not. Arm had noted that the X2 can have quite lower power at the same peak performance point of the X1, if Qualcomm’s marketing materials refer to such a comparison, then the numbers might make sense.

The X2 core is configured with 1MB of L2 cache, while the three Cortex-X710 cores have 512KB each. The middle cores here are clocked slightly higher at 2.5GHz this year, a little 80MHz jump over the previous generation. Usually, the middle cores pay more attention to the power budget, so maybe this slightly increase does represent more accurately the process node improvements.
Lastly, the new chip also makes use of four Cortex-A510 cores at 1.8GHz. Unlike the Dimensity 9000 from a couple of weeks back, Qualcomm does make use of Arm’s new “merged-core” approach of the new microarchitecture, meaning that the chip actually has two Cortex-A510 complexes with two cores each, sharing a common NEON/SIMD pipeline and L2 cache. The merged core approach is meant to achieve better area efficiency. Qualcomm rationalized the approach by saying that in everyday use cases with fewer threads active and overall low activity, having a single core able to access a larger L2 cache shared by two cores can result in better performance and efficiency. Unfortunately even while making this comment, the company wouldn’t actually detail what the L2 size was, whether it’s 512KB or 256KB – if it’s the latter, then the configuration definitely isn’t as aggressive as the Dimensity 9000.
The new Armv9 CPU IPs from Arm also came with a new generation DSU (DynamiQ Shared Unit, the cluster IP) which the new Snapdragon makes use of. Qualcomm here opted for a 6MB L3 cache size, noting that this was a decision in balancing out system performance across target workloads.
As for system caches, Qualcomm mentioned that the chip remains unchanged with a 4MB cache, and the memory controllers are still 3200MHz LPDDR5 (4x 16bit channels). It’s to be noted that, as with last year’s Snapdragon 888, the CPUs no longer have access to the system cache, in order to improve DRAM latency. We can’t help but make comparisons to MediaTek’s Dimensity 9000, which likely will have worse DRAM latency, but also offer up to 14MB of shared caches to the CPUs versus just 6MB on the Snapdragon 8 Gen 1. How the two chips will compare to each other remains to be seen in actual commercial devices.
GPU: New Adreno architecture with no name
Back in the day, Qualcomm’s Adreno GPU architectures were easy to identify in terms of their family as well as performance levels. Particularly on the architecture side, the Adreno 600 series started off with the Adreno 630 in the Snapdragon 845 a few years ago, but unlike in previous iterations from the 400- and 500 series, we remained with that high-level description up until the Snapdragon 888 series.
The Snapdragon 8 Gen 1 here changes things, and frankly, Qualcomm did a quite horrible job at marketing what they have this time around. The new GPU name completely drops any model number, and as such doesn’t immediately divulge that it’s part of a larger microarchitecture shift that in the past would have been marketed as a new Adreno series.
Qualcomm notes that from an extremely high-level perspective, the new GPU might look similar to the previous generations, however there are large architectural changes included that are meant to improve performance and efficiency. Qualcomm gave examples such as concurrent processing optimizations that are meant to give large boosts in performance to real-world workloads that might not directly show up in benchmarks. Another example was that the GPU’s “GMEM” saw large changes this generation, such as an increase of 33% of the cache (to 4MB), and now being both a read & write cache rather than just a writeback cache for DRAM traffic optimizations.

The high-level performance claims are 30% faster peak performance, or 25% power reduction at the same performance as the Snapdragon 888. Qualcomm also uncharacteristically commented on the situation of peak power figures and the current situation in the market. Last year, Qualcomm rationalized the Snapdragon 888’s high peak GPU power figures by noting that this is what vendors had demanded in response to what we saw from other players, notably Apple, and that vendors would be able to achieve better thermal envelopes in their devices. Arguably, this strategy ended up as being quite disastrous and negative in terms of perception for Qualcomm, and I feel that in this year’s briefing we saw Quaclomm attempt to distance themselves more from the situation, largely by outright saying that the only point of such peak performance and power figures is for vendors to achieve higher first-run benchmarking numbers.
Unfortunately, unlike Apple, who actually use their GPU’s peak performance figures in transient compute workloads such as camera processing, currently the Android ecosystem just doesn’t make any advanced use of GPU compute. This admission was actually a breath of fresh air and insight into the situation, as it’s been something I’ve especially noted in our Kirin 9000, Snapdragon 888 and Exynos 2100 and Tensor deep-dives in criticizing all the new chips. It’s an incredibly stupid situation that, as long as the media continues to put weight on peak performance figures, won’t be resolved any time soon, as the chip vendors will have a hard time saying no to their customer’s requests to operate the silicon in this way.
Qualcomm states that one way to try to alleviate this new focus on peak performance is to change the way the GPU performance and power curve behaves. The team stated that they’ve gone in to change the architecture to try to flatten the curve, to not only achieve those arguably senseless peak figures, but actually focus on making larger improvements in the 3-5W power range, a range where the Snapdragon 888 last year didn’t significantly improve upon the Snapdragon 865.
That being said, even with a 25% decrease in power at similar Snapdragon 888 performance, the new Snapdragon 8 Gen 1 likely still won’t be able to compete against Apple’s A14 or A15 chips. MediaTek’s Dimensity 9000 also should also be notably more efficient than the new Snapdragon at equal performance levels given the claimed efficiency figures, so it still looks like Qualcomm’s choice of going with a Samsung process node, even this new 4nm one, won’t close the gap to the TSMC competitors.








{kind=link}
219 Comments
View All Comments
mode_13h - Friday, December 3, 2021 - link
> HEVC is the winner in terms of adoption as hardware support beats claims made companies.Talk about an unfair comparison! HEVC was standardized long before AV1 was a thing!
name99 - Thursday, December 2, 2021 - link
That's an exceptionally naive analysis.Most of the member of AOM have zero interest in ACTUALLY supporting yet another codec. AV1 (and AV2) exist purely to ensure that the REAL codecs (VVC, and EVC as the royalty-free version) come with reasonable terms so no-one (*cough* MPEG LA *cough*) tries to pull some shit, like kinda-sorta happened with h.264 in the early days of streaming.
Zoolook - Wednesday, December 8, 2021 - link
Qualcomm is one of the companies behind HEVC, they get license money for every hevc enabled part that sells, why would they support the competition?They won't unless they really have to, and so far they don't.
name99 - Thursday, December 2, 2021 - link
Of course VVC use is non-existent. It was finalized in 2020 (as opposed to AV1 in 2018).Apple had their first h.265 decoder in iPhones a year after 265 was finalized BUT this was not really publicized until a year later, so that when Apple talked about h.265 as their new preferred codec, they could point to a large pre-existing HW base.
Chances are they will follow the same strategy for 266, suggesting that A15 may already have a decoder as part of the media block, but h.266 will not be discussed as part of Apple's preferred codecs until at least next year.
I *think* Mediatek have a decoder, so it may be present on their chipsets. But all these things take time...
name99 - Thursday, December 2, 2021 - link
AOM and AV1 have done their job.- licensing around future codecs will be more sane, without any backsliding
- EVC is essentially equivalent to AV1 in performance and cpu cost, but is an ITU/ISO standard AND is royalty-free
There's just no job left for AV1 to do except persist as a *possibility* if someone owning a patent that's part of VVC behaves stupidly.
mode_13h - Friday, December 3, 2021 - link
> AOM and AV1 have done their job.That seems premature. For it to be a credible threat, AV1 needs hardware support. Otherwise, if there's a situation with lots of VVC hardware and no AV1 hardware, then the VVC patent holders might feel they have the leverage to force stricter licensing terms.
vladx - Wednesday, December 1, 2021 - link
HEVC us used by Netflix, Amazon Prime and pretty much everything outside Google's ecosystem. Just because they recently adopted AV1, doesn't mean Netflix has dropped HEVC which has much wider hardware support.GeoffreyA - Wednesday, December 1, 2021 - link
vladx, HEVC may be more widespread, but was a lacklustre codec in many ways. Arguably, it never reached the excellence of its predecessor. AV1 is noticeably better than HEVC, and is in the same class, but slightly behind, VVC.vladx - Wednesday, December 1, 2021 - link
What do you mean? It has 50% better compression than H.264 and it's even more efficient than AV1 in terms of bandwidth usage as comparable quality settings, AV1 is only better space-wise which is less important since more space is cheaper to buy than more bandwidth. Only Google decided to cheapen out on paying royalties because of their NIH syndrome but that doesn't make HEVC lackluster as a codec in any way whatsoever.vladx - Wednesday, December 1, 2021 - link
And when I ssay that HEVC is more efficient bandwidth-wise than AV1, I'm referring of course to resolutions of 4K and above.. AV1 is better at 1080p and below but those resolutions are not really a concern in terms of bandwidth consumption.